作者:手机用户2502877397 | 来源:互联网 | 2023-10-11 15:47
篇首语:本文由编程笔记#小编为大家整理,主要介绍了08 spark 集群搭建相关的知识,希望对你有一定的参考价值。
前言
呵呵 最近有一系列环境搭建的相关需求
记录一下
spark 三个节点 : 192.168.110.150, 192.168.110.151, 192.168.110.152
150 为 master, 151 为 slave01, 152 为 slave02
三台机器都做了 trusted shell
spark 版本是 spark-3.2.1-bin-hadoop2.7
spark 集群搭建
spark 三个节点 : 192.168.110.150, 192.168.110.151, 192.168.110.152
1. 基础环境准备
192.168.110.150, 192.168.110.151, 192.168.110.152 上面安装 jdk, 上传 spark 的安装包
安装包来自于 Downloads | Apache Spark
2. spark 配置调整
复制如下 三个配置文件, 进行调整, 调整了之后 scp 到 slave01, slave02 上面
root@master:/usr/local/ProgramFiles/spark-3.2.1-bin-hadoop2.7# cp conf/spark-defaults.conf.template conf/spark-defaults.conf
root@master:/usr/local/ProgramFiles/spark-3.2.1-bin-hadoop2.7# cp conf/spark-env.sh.template conf/spark-env.sh
root@master:/usr/local/ProgramFiles/spark-3.2.1-bin-hadoop2.7# cp conf/workers.template conf/workers
更新 workers
# A Spark Worker will be started on each of the machines listed below.
slave01
slave02
更新 spark-defaults.conf
spark.master spark://master:7077
# spark.eventLog.enabled true
# spark.eventLog.dir hdfs://namenode:8021/directory
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.driver.memory 1g
# spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"
更新 spark-env.sh
export JAVA_HOME=/usr/local/ProgramFiles/jdk1.8.0_291
export HADOOP_HOME=/usr/local/ProgramFiles/hadoop-2.10.1
export HADOOP_CONF_DIR=/usr/local/ProgramFiles/hadoop-2.10.1/etc/hadoop
export SPARK_DIST_CLASSPATH=$(/usr/local/ProgramFiles/hadoop-2.10.1/bin/hadoop classpath)
export SPARK_MASTER_HOST=master
export SPARK_MASTER_PORT=7077
3. 启动集群
master 所在的机器执行 start-all.sh
root@master:/usr/local/ProgramFiles/spark-3.2.1-bin-hadoop2.7# ./sbin/start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /usr/local/ProgramFiles/spark-3.2.1-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.master.Master-1-master.out
slave01: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/ProgramFiles/spark-3.2.1-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-slave01.out
slave02: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/ProgramFiles/spark-3.2.1-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-slave02.out
root@master:/usr/local/ProgramFiles/spark-3.2.1-bin-hadoop2.7#
测试集群
使用 spark-submit 提交 SparkPI 迭代 1000 次
spark-submit --class org.apache.spark.examples.SparkPi /usr/local/ProgramFiles/spark-3.2.1-bin-hadoop2.7/examples/jars/spark-examples_2.12-3.2.1.jar 1000
java driver 提交 spark 任务
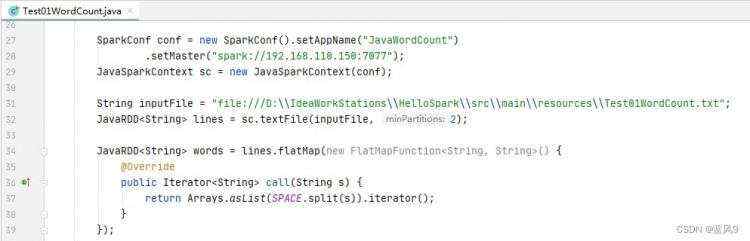
spark web ui 监控页面

完





 京公网安备 11010802041100号
京公网安备 11010802041100号