第02讲:Hadoop 发行版选型和伪分布式平台的构建
高俊峰(南非蚂蚁)
本课时主要介绍 Hadoop 发行版选型以及伪分布式平台的构建。
Hadoop 发行版介绍与选择
到目前为止,你应该初步了解了大数据以及 Hadoop 相关的概念了。本课时我将介绍 Hadoop 如何快速使用,由于 Hadoop 平台的构建过程相当复杂,它涉及系统、网络、存储、配置与调优,但为了能让你尽快尝鲜体验一下 Hadoop 的功能和特性,我们先一起构建一个伪分布式 Hadoop 集群,也就是一个假的 Hadoop 集群,麻雀虽小,但五脏俱全。
伪分布式 Hadoop 集群能够实现 Hadoop 的所有功能,并且部署简单,因此非常适合新手进行学习、开发、测试等工作。
Hadoop 有哪些发行版
与 Linux 有众多发行版类似,Hadoop 也有很多发行版本,但基本上分为两类,即开源社区版和商业付费版。社区版是指由 Apache 软件基金会维护的版本,是官方维护的版本体系;商业版付费版是指由第三方商业公司在社区版 Hadoop 基础上进行了一些修改、整合以及各个服务组件兼容性测试而发行的稳定版本,比较著名的有 Cloudera 的 CDP、CDH、Hortonworks 的 Hortonworks Data Platform(HDP)、mapR 等。
在这些商业 Hadoop 发行版中,为了吸引用户的使用,厂商也提供了一些开源产品作为诱饵,比如 Cloudera 的 CDH 发行版、Hortonworks 的 HDP 发行版等,所以,目前而言,不收费的 Hadoop 版本主要有三个,即 Apache Hadoop、Cloudera 的 CDH 版本、Hortonworks 的 HDP。
经过多年的发展,Cloudera 的 CDH 版本和 Hortonworks 的 HDP 版本在大数据开源社区互为竞争,两分天下,占据了国内、外 90% 以上的大数据市场,但随着公有云市场趋于成熟,很多云厂商在云端也提供了 Hadoop 服务,比如亚马逊的 Elastic MapReduce(EMR)、Microsoft Azure Hadoop、阿里云 E-MapReduce(Elastic MapReduce,EMR)等,这些基于云的大数据服务抢走了 Cloudera 和 Hortonworks 的大部分客户,所谓天下大势,分久必合,合久必分,最终,Cloudera 和 Hortonworks 从竞争走到了一起,他们相爱了。
下面我们来聊下常用的三个 Hadoop 发行版本,看看他们的产品特点以及如何选型。
Apache Hadoop 发行版本
Apache Hadoop 是最原始的 Hadoop 发行版本,目前总共发行了三个大版本,即 Hadoop1.x、Hadoop2.x、Hadoop3.x,每个版本的功能特性如下表所示:
Apache Hadoop 发行版提供源码包和二进制包两种形式下载,对我们来说,下载二进制包更加方便。
Hortonworks Hadoop 发行版
Hortonworks 的主打产品是 HDP,同样是 100% 开源的产品,它最接近 Apache Hadoop 的版本,除此之外,HDP 还包含了 Ambari,这是一款开源的 Hadoop 管理系统。它可以实现统一部署、自动配置、自动化扩容、实时状态监控等,是个功能完备的大数据运维管理平台。
在使用 HDP 发行版时,可以通过 Ambari 管理功能,实现 Hadoop 的快速安装和部署,并且对大数据平台的运维也有很大帮助,可以说 Ambari 实现了与 HDP 的无缝整合。
HDP 至今也发行了三个版本,即 HDP1.x、HDP2.x 和 HDP3.x,跟 Apache Hadoop 发行的大版本遥相呼应,而 HDP 发行版的安装是基于 Ambari 实现的,通过 HDP 提供的 rpm 文件,可以在 Ambari 平台实现自动化的安装和扩容,后面会做详细介绍。
Cloudera Hadoop 发行版
Cloudera 是最早将 Hadoop 商用的公司,目前旗下的产品主要有 CDH、Cloudera Manager、Cloudera Data Platform(CDP)等,下表简单介绍了这些产品的特点。
CDH 支持 yum/apt 包、RPM 包、tarball 包、Cloudera Manager 四种方式安装,但在最新版本 CDH6 中已经不提供 tarball 方式了,这也是 Cloudera 进行产品整合的一个信号。
Cloudera 在宣布与 Hortonworks 合并后,他们使用了类似红帽公司的开源战略,提供了订阅机制来收费,同时为开发人员和试用提供了无支援的免费版本,并向商业用户提供订阅付费的版本。至此,Cloudera 成为全球第二大开源公司(红帽第一)。
看到这里,也许会担心,这么好的开源版本,后面是不是就不能免费使用了呢,答案是否定的,Cloudera 承诺 CDH 和 HDP 平台将可以继续使用,直到 2022 年。
如何选择发行版
作为用户,应该如何选择呢,经过多年对 Hadoop 的使用,我的建议是:对于初学入门的话,建议选择 Apache Hadoop 版本最好,因为它的社区活跃、文档、资料详实。而如果要在企业生产环境下使用的话,建议需要考虑以下几个因素:
-
是否为开源产品(是否免费),这点很重要;
-
是否有稳定的发行版本,开发版是不能用在生产上的;
-
是否已经接受过实践的检验,看看是否有大公司在用(自己不能当小白鼠);
-
是否有活跃的社区支持、充足的资料,因为遇到问题,我们可以通过社区、搜索等网络资源来解决问题。
在国内大型互联网企业中,使用较多的是 CDH 或 HDP 发行版本,个人推荐采用 HDP 发行版本,原因是部署简单、性能稳定。
伪分布式安装 Hadoop 集群
为了让你快速了解 Hadoop 功能和用途,先通过伪分布式来安装一个 Hadoop 集群,这里采用 Apache Hadoop 发行版的二进制包进行快速部署。完全分布式 Hadoop 集群后面将会进行更深入的介绍。
安装规划
伪分布式安装 Hadoop 只需要一台机器,硬件配置最低为 4 核 CPU、8G 内存即可,我们采用 Hadoop-3.2.1 版本,此版本要求 Java 版本至少是 JDK8,这里以 JDK1.8.0_171、CentOS7.6 为例进行介绍。根据运维经验以及后续的升级、自动化运维需要,将 Hadoop 程序安装到 /opt/hadoop 目录下,Hadoop 配置文件放到 /etc/hadoop 目录下。
安装过程
下载 Apache Hadoop 发行版本的 hadoop-3.2.1.tar.gz 二进制版本文件,其安装非常简单,只需解压文件即可完成安装,操作过程如下:
[root@hadoop3server hadoop]#useradd hadoop
[root@hadoop3server ~]#mkdir /opt/hadoop
[root@hadoop3server ~]#cd /opt/hadoop
[root@hadoop3server hadoop]#tar zxvf hadoop-3.2.1.tar.gz
[root@hadoop3server hadoop]#ln -s hadoop-3.2.1 current
[root@hadoop3server hadoop]#chown -R hadoop:hadoop /opt/hadoop
注意,将解压开的 hadoop-3.2.1.tar.gz 目录软链接到 current 是为了后续运维方便,因为可能涉及 Hadoop 版本升级、自动化运维等操作,这样设置后,可以大大减轻运维工作量。
Hadoop 程序安装完成后,还需要拷贝配置文件到 /etc/hadoop 目录下,执行如下操作:
[root@hadoop3server ~]#mkdir /etc/hadoop
[root@hadoop3server hadoop]#cp -r /opt/hadoop/current/etc/hadoop /etc/hadoop/conf
[root@hadoop3server hadoop]# chown -R hadoop:hadoop /etc/hadoop
这样,就将配置文件放到 /etc/hadoop/conf 目录下了。
接着,还需要安装一个 JDK,这里使用的是 JDK 1.8.0_171,将其安装到 /usr/java 目录下,操作过程如下:
[root@hadoop3server ~]#mkdir /usr/java
[root@hadoop3server ~]#cd /usr/java
[root@hadoop3server java]#tar zxvf jdk-8u171-linux-x64.tar.gz
[root@hadoop3server java]#ln -s jdk1.8.0_171 default
这个操作过程的最后一步,做这个软连接,也是为了后续运维自动化配置、升级方便。
最后一步,还需要创建一个 Hadoop 用户,然后设置 Hadoop 用户的环境变量,配置如下:
[root@hadoop3server ~]#useradd hadoop
[root@hadoop3server ~]# more /home/hadoop/.bashrc
# .bashrc
# Source global definitions
if [ -f /etc/bashrc ]; then
. /etc/bashrc
fi
# User specific aliases and functions
export JAVA_HOME=/usr/java/default
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH
export HADOOP_HOME=/opt/hadoop/current
export HADOOP_MAPRED_HOME=${HADOOP_HOME}
export HADOOP_COMMON_HOME=${HADOOP_HOME}
export HADOOP_HDFS_HOME=${HADOOP_HOME}
export HADOOP_YARN_HOME=${HADOOP_HOME}
export HTTPFS_CATALINA_HOME=${HADOOP_HOME}/share/hadoop/httpfs/tomcat
export CATALINA_BASE=${HTTPFS_CATALINA_HOME}
export HADOOP_CONF_DIR=/etc/hadoop/conf
export HTTPFS_COnFIG=/etc/hadoop/conf
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
这里创建的 Hadoop 用户,就是以后管理 Hadoop 平台的管理员用户,所有对 Hadoop 的管理操作都需要通过这个用户来完成,这一点需注意。
另外,在配置的环境变量中,以下两个要特别注意,如果没有配置或者配置错误,将导致某些服务无法启动:
-
HADOOP_HOME 是指定 Hadoop 安装程序的目录
-
HADOOP_CONF_DIR 是指定 Hadoop 配置文件目录
到这里为止,Hadoop 已经基本安装完成了,是不是很简单!
配置 Hadoop 参数
Hadoop 安装完成后,先来了解一下其安装目录下几个重要的目录和文件,这里将 Hadoop 安装在了 /opt/hadoop/current 目录下,打开这个目录,需要掌握的几个目录如下表所示:
了解完目录的功能后,就开始进行配置操作了,Hadoop 的配置相当复杂,不过这些是后面要讲的内容。而在伪分布模式下,仅仅需要修改一个配置文件即可,该文件是 core-site.xml,此文件目前位于 /etc/hadoop/conf 目录下,在此文件 标签下增加如下内容:
其中,fs.defaultFS 属性描述的是访问 HDFS 文件系统的 URI 加一个 RPC 端口, 不加端口的话,默认是 8020。另外,hadoop3server 可以是服务器的主机名,也可以是任意字符,但都需要将此标识在服务器的 /etc/hosts 进行解析,也就是添加如下内容:
172.16.213.232 hadoop3server
这里的 172.16.213.232 就是安装 Hadoop 软件的服务器 IP 地址。
启动 Hadoop 服务
配置操作完成后,下面就可以启动 Hadoop 服务了,虽然是伪分布模式,但 Hadoop 所有的服务都必须要启动,需要启动的服务有如下几个。
服务的功能和用途,先介绍这么多,后面将会进行更深入的阐述。接下来,要启动 Hadoop 集群的服务,必须以 Hadoop 用户来执行,并且每个服务的启动是有先后顺序的,下面依次启动每个服务。
(1)启动 NameNode 服务
首先需要对 NameNode 进行格式化,命令如下:
[root@hadoop3server ~]#su - hadoop
[hadoop@hadoop3server ~]$ cd /opt/hadoop/current/bin
[hadoop@hadoop3server bin]$ hdfs namenode -format
然后就可以启动 NameNode 服务了,操作过程如下:
[hadoop@hadoop3server conf]$ hdfs --daemon start namenode
[hadoop@hadoop3server conf]$ jps|grep NameNode
27319 NameNode
通过 jps 命令查看 NameNode 进程是否正常启动,如果无法正常启动,可以查看 NameNode 启动日志文件,检查是否有异常信息抛出,这里的日志文件路径是:/opt/hadoop/current/logs/hadoop-hadoop-namenode-hadoop3server.log。
NameNode 启动完成后,就可以通过 Web 页面查看状态了,默认会启动一个 http 端口 9870,可通过访问地址:http://172.16.213.232:9870 查看 NameNode 服务状态,如下图所示:
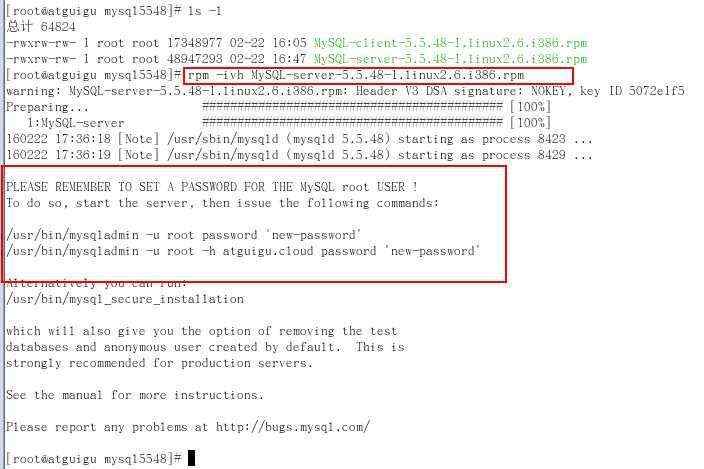
在上图中,红框标注的几个重点信息需要关注,第一个是 Hadoop 中 namenode 的访问地址为 hdfs://hadoop3server:8020,这是我们在配置文件中指定过的;另外还有 Hadoop 的版本、运行模式、容量、“Live node”及“Dead node”,下面逐个解释。
运行模式显示“Safe mode is ON”,这表示目前 namenode 处于安全模式下了,为什么呢,其实图中已经说明原因了,Namenode 在启动时,会检查 DataNode 的状态,如果 DataNode 上报的 block 个数达到了元数据记录的 block 个数的 0.999 倍才可以离开安全模式,否则一直运行在安全模式。安全模式也叫只读模式,此模式下,对 HDFS 上的数据无法进行写操作。因为现在还没启动 DataNode 服务,所以肯定是处于安全模式下。
HDFS 容量,Configured Capacity 目前显示为 0,这也是因为还没启动 DataNode 服务导致的,等启动后,应该就有容量显示了。
“Live node”及“Dead node”分别显示目前集群中活跃的 DataNode 节点和故障(死)DataNode 节点,运维经常通过监控这个页面中“Dead node”的值来判断集群是否出现异常。
(2)启动 secondarynamenode 服务
在 NameNode 服务启动完成后,就可以启动 secondarynamenode 服务了,直接执行如下命令:
[hadoop@hadoop3server ~]$ hdfs --daemon start secondarynamenode
[hadoop@hadoop3server ~]$ jps|grep SecondaryNameNode
29705 SecondaryNameNode
与 NameNode 类似,如果无法启动 secondarynamenode 进程,可以通过 /opt/hadoop/current/logs/hadoop-hadoop-secondarynamenode-hadoop3server.log 文件检查 secondarynamenode 启动日志中是否存在异常。
(3)启动 DataNode 服务
现在是时候启动 DataNode 服务了,直接执行如下命令:
[hadoop@hadoop3server ~]$ hdfs --daemon start datanode
[hadoop@hadoop3server ~]$ jps|grep DataNode
3876 DataNode
如果无法启动,可通过查看 /opt/hadoop/current/logs/hadoop-hadoop-datanode-hadoop3server.log 文件检查 datanode 启动过程是否存在异常。
到这里为止,分布式文件系统 HDFS 服务已经启动完成,可以对 HDFS 文件系统进行读、写操作了。现在再次通过http://172.16.213.232:9870 查看 NameNode 服务状态页面,如图所示:
从图中可以看出,HDFS 集群中安全模式已经关闭,并且集群容量和活跃节点已经有数据了,这是因为 datanode 服务已经正常启动了。
(4)启动 ResourceManager 服务
接下来,还需要启动分布式计算服务,首先启动的是 ResourceManager,启动方式如下:
[hadoop@hadoop3server ~]$ yarn --daemon start resourcemanager
[hadoop@hadoop3server ~]$ jps|grep ResourceManager
4726 ResourceManager
注意,启动 resourcemanager 服务的命令变成了 yarn,而不是 hdfs,记住这个细节。
同理,如果 ResourceManager 进程无法启动,可以通过检查 /opt/hadoop/current/logs/hadoop-hadoop-resourcemanager-hadoop3server.log 日志文件来排查 ResourceManager 启动问题。
ResourceManager 服务启动后,会默认启动一个 http 端口 8088,可通过访问 http://172.16.213.232:8088 查看 ResourceManager 的 Web 状态页面,如下图所示:
在上图中,需要重点关注的是 ResourceManager 中可用的内存资源、CPU 资源数及活跃节点数,目前看来,这些数据都是 0,是因为还没有 NodeManager 服务启动。
(5)启动 NodeManager 服务
在启动完成 ResourceManager 服务后,就可以启动 NodeManager 服务了,操作过程如下:
[hadoop@hadoop3server ~]$ yarn --daemon start nodemanager
[hadoop@hadoop3server ~]$ jps|grep NodeManager
8853 NodeManager
如果有异常,可通过检查 /opt/hadoop/current/logs/hadoop-hadoop-nodemanager-hadoop3server.log 文件来排查 NodeManager 问题。
(6)启动 Jobhistoryserver 服务
等待 ResourceManager 和 NodeManager 服务启动完毕后,最后还需要启动一个 Jobhistoryserver 服务,操作过程如下:
[hadoop@hadoop3server ~]$ mapred --daemon start historyserver
[hadoop@hadoop3server ~]$ jps|grep JobHistoryServer
1027 JobHistoryServer
注意,启动 Jobhistoryserver 服务的命令变成了 mapred,而非 yarn。这是因为 Jobhistoryserver 服务是基于 MapReduce 的,Jobhistoryserver 服务启动后,会运行一个 http 端口,默认端口号是 19888,可以通过访问此端口查看每个任务的历史运行情况,如下图所示:
至此,Hadoop 伪分布式已经运行起来了,可通过 jps 命令查看各个进程的启动信息:
[hadoop@hadoop3server ~]$ jps
12288 DataNode
1027 JobHistoryServer
11333 NameNode
1158 Jps
29705 SecondaryNameNode
18634 NodeManager
19357 ResourceManager
不出意外的话,会输出每个服务的进程名信息,这些输出表明 Hadoop 服务都已经正常启动了。现在,可以在 Hadoop 下愉快的玩耍了。
运用 Hadoop HDFS 命令进行分布式存储
Hadoop 的 HDFS 是一个分布式文件系统,要对 HDFS 进行操作,需要执行 HDFS Shell,跟 Linux 命令很类似,因此,只要熟悉 Linux 命令,可以很快掌握 HDFS Shell 的操作。
下面看几个例子,你就能迅速知道 HDFS Shell 的用法, 需要注意,执行 HDFS Shell 建议在 Hadoop 用户或其他普用用户下执行。
(1)查看 hdfs 根目录数据,可通过如下命令:
[hadoop@hadoop3server ~]$ hadoop fs -ls /
通过这个命令的输出可知,刚刚创建起来的 HDFS 文件系统是没有任何数据的,不过可以自己创建文件或目录。
(2)在 hdfs 根目录创建一个 logs 目录,可执行如下命令:
[hadoop@hadoop3server ~]$ hadoop fs -mkdir /logs
(3)从本地上传一个文件到 hdfs 的 /logs 目录下,可执行如下命令:
[hadoop@hadoop3server ~]$ hadoop fs -put /data/test.txt /logs
[hadoop@hadoop3server ~]$ hadoop fs -put /data/db.gz /logs
[hadoop@hadoop3server ~]$ hadoop fs -ls /logs
Found 2 items
-rw-r--r-- 3 hadoop supergroup 150569 2020-03-19 07:11 /logs/test.txt
-rw-r--r-- 3 hadoop supergroup 95 2020-03-24 05:11 /logs/db.gz
注意,这里的 /data/test.txt 及 db.gz 是操作系统下的一个本地文件,通过执行 put 命令,可以看到,文件已经从本地磁盘传到 HDFS 上了。
(4)要查看 hdfs 中一个文本文件的内容,可执行如下命令:
[hadoop@hadoop3server ~]$ hadoop fs -cat /logs/test.txt
[hadoop@hadoop3server ~]$ hadoop fs -text /logs/db.gz
可以看到,在 HDFS 上的压缩文件通过“-text”参数也能直接查看,因为默认情况下 Hadoop 会自动识别常见的压缩格式。
(5)删除 hdfs 上一个文件,可执行如下命令:
[hadoop@hadoop3server ~]$ hadoop fs -rm -r /logs/test.txt
注意,HDFS 上面的文件,只能创建和删除,无法更新一个存在的文件,如果要更新 HDFS 上的文件,需要先删除这个文件,然后提交最新的文件即可。除上面介绍的命令之外,HDFS Shell 还有很多常用的命令,这个在后面会有专门课时来讲解。
在 Hadoop 中运行 Mapreduce 程序
要体验 Hadoop 的分布式计算功能,这里借用 Hadoop 安装包中附带的一个 mapreduce 的 demo 程序,做个简单的 MR 计算。
这个 demo 程序位于 $HADOOP_HOME/share/hadoop/mapreduce 路径下,这个环境下的路径为 /opt/hadoop/current/share/hadoop/mapreduce,在此目录下找到一个名为 hadoop-mapreduce-examples-3.2.1.jar 的 jar 文件,有了这个文件下面的操作就简单多了。
单词计数是最简单也是最能体现 MapReduce 思想的程序之一,可以称为 MapReduce 版“Hello World”,hadoop-mapreduce-examples-3.2.1.jar 文件中包含了一个 wordcount 功能,它主要功能是用来统计一系列文本文件中每个单词出现的次数。下面开始执行分析计算。
(1)创建一个新文件
创建一个测试文件 demo.txt,内容如下:
Linux Unix windows
hadoop Linux spark
hive hadoop Unix
MapReduce hadoop Linux hive
windows hadoop spark
(2)将创建的文件存入 HDFS
[hadoop@hadoop3server ~]$ hadoop fs -mkdir /demo
[hadoop@hadoop3server ~]$ hadoop fs -put /opt/demo.txt /demo
[hadoop@hadoop3server ~]$ hadoop fs -ls /demo
Found 1 items
-rw-r--r-- 3 hadoop supergroup 105 2020-03-24 06:02 /demo/demo.txt
这里在 HDFS 上创建了一个目录 /demo,然后将刚才创建好的本地文件 put 到 HDFS 上,这里举例是一个文件,如果要统计多个文件内容,将多个文件都上传到 HDFS 的 /demo 目录即可。
(3)执行分析计算任务
下面开始执行分析任务:
[hadoop@hadoop3server ~]$ hadoop jar /opt/hadoop/current/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar wordcount /demo /output
[hadoop@hadoop3server ~]$ hadoop fs -ls /output
Found 2 items
-rw-r--r-- 3 hadoop supergroup 0 2020-03-24 06:05 /output/_SUCCESS
-rw-r--r-- 3 hadoop supergroup 61 2020-03-24 06:05 /output/part-r-00000
[hadoop@hadoop3server ~]$ hadoop fs -text /output/part-r-00000
Linux 3
MapReduce 1
Unix 2
hadoop 4
hive 2
spark 2
windows 2
在上面的操作中,通过执行“hadoop jar”后面跟上 jar 包示例文件,并给出执行的功能是 wordcount,即可完成任务的执行,请注意,最后的两个路径都是 HDFS 上的路径,第一个路径是分析读取文件的目录,必须存在;第二个路径是分析任务输出结果的存放路径,必须不存在,分析任务会自动创建这个目录。
任务执行完毕后,可以查看 /output 目录下有两个文件,其中:
-
_SUCCESS,任务完成标识,表示执行成功;
-
part-r-00000,表示输出文件名,常见的名称有 part-m-00000、part-r-00001,其中,带 m 标识的文件是 mapper 输出,带 r 标识的文件是 reduce 输出的,00000 为 job 任务编号,part-r-00000 整个文件为结果输出文件。
通过查看 part-r-00000 文件内容,可以看到 wordcount 的统计结果。左边一列是统计的单词,右边一列是在文件中单词出现的次数。
(4)在 ResourceManager 的 Web 页面展示运行任务
细心的你可能已经发现了,上面在命令行执行的 wordcount 统计任务虽然最后显示是执行成功了,统计结果也正常,但是在 ResourceManager 的 Web 页面并没有显示出来。
究其原因,其实很简单:这是因为那个 mapreduce 任务并没有真正提交到 yarn 上来,因为默认 mapreduce 的运行环境是 local(本地),要让 mapreduce 在 yarn 上运行,需要做几个参数配置就行了。
需要修改的配置文件有两个,即 mapred-site.xml 和 yarn-site.xml,在你的配置文件目录,找到它们。
打开 mapred-site.xml 文件,在 标签内添加如下内容:
其中,mapreduce.framework.name 选项就是用来指定 mapreduce 的运行时环境,指定为 yarn 即可,下面的三个选项是指定 mapreduce 运行时一些环境信息。
最后,修改另一个文件 yarn-site.xml,添加如下内容到 标签中:
其中,yarn.nodemanager.aux-services 选项代表可在 NodeManager 上运行的扩展服务,需配置成 mapreduce_shuffle,才可运行 MapReduce 程序。
配置修改完成后,需要重启 ResourceManager 与 nodemanager 服务才能使配置生效。
现在,我们再次运行刚才的那个 mapreduce 的 wordcount 统计,所有执行的任务都会在 ResourceManager 的 Web 页面展示出来,如下图所示:
从图中可以清晰的看出,执行任务的 ID 名、执行任务的用户、程序名、任务类型、队列、优先级、启动时间、完成时间、最终状态等信息。从运维角度来说,这个页面有很多信息都需要引起关注,比如任务最终状态是否有失败的,如果有,可以点击倒数第二列“Tracking UI”下面的 History 链接查看日志进行排查问题。
Namenode 的 Web 页面和 ResourceManager 的 Web 页面在进行大数据运维工作中,经常会用到,这些 Web 界面主要用来状态监控、故障排查,更多使用细节和技巧,后面课时会做更加详细的介绍。
总结
怎么样,现在可以感受到 Hadoop 集群的应用场景了吧!虽然本课时介绍的是伪分别式环境,但与真实的完全分布式 Hadoop 环境实现的功能完全一样。上面的例子中我只是统计了一个小文本中单词的数量,你可能会说,这么点数据,手动几秒钟就算出来了,真没看到分布式计算有什么优势。没错,在小量数据环境中,使用 Yarn 分析是没有意义的,而如果你有上百 GB 甚至 TB 级别的数据时,就能深刻感受到分布式计算的威力了。但有一点请注意,不管数据量大小,分析的方法都是一样的,所以,你可以按照上面执行 wordcount 的方法去读取 GB 甚至 TB 级别的数据。










 京公网安备 11010802041100号
京公网安备 11010802041100号