需要存储哪些状态才能允许可恢复的哈希计算?
这个问题只与现实世界的问题间接相关,更令人感兴趣.我不知道当前的真实哈希算法如何在内部工作.
我知道典型的哈希计算(和CRC计算等)逐步工作,依次更新每个字节/字的某些状态[事实证明,算法一次只能处理一个块,尽管接口通常会自动处理].因此,稍后可以恢复部分完成的哈希计算 - 存储该状态,然后重新加载并继续您离开的位置.关于SO的问题已经存在,但它们似乎都与特定的图书馆有关.
从CRC-16的古老知识(是的,真的 - 由于过时的文件格式),我的印象是CRC值本身就是你需要存储以恢复计算的所有状态.显然,实现可以用奇怪的方式编写,但原则上到目前为止看到的文件部分内容的CRC-16是从该点恢复计算所需的完整状态.
现在使用的所有常见哈希计算都是如此吗?特别是MD5,SHA-1和SHA-256.或者是否必须存储其他(附加或替代)状态才能恢复计算?
显然需要从文件中恢复的位置,但除此之外,您需要存储什么样的精确状态才能使用公共散列函数恢复散列计算.
对于额外的奖励积分 - 如何在C++中使用Crypto ++访问该状态?(链接或对文档正确部分的引用可能非常有用).
我将其标记为"算法",因为这是此处的重点 - 来自现实世界算法的要求,而不是任何特定语言或库的实现.
-
今天大多数加密哈希,包括MD5,SHA-1和SHA-2系列,均基于Merkle-Damgård结构.
在这种结构中,通过将输入分成固定长度的块来处理输入,固定长度的块一次一个地馈送到"混合函数"中,该"混合函数"将算法的内部状态(也是固定长度)不可逆地混合在一起.比特串).在输入结束时,生成的内部状态将进一步不可逆转地转换为防止某些类型的攻击:
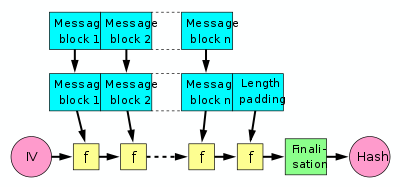
(即将推出的SHA-3哈希标准是基于较新的加密海绵结构,它在某些细节上有所不同,但在这里讨论的一般水平上并不显着.)
如果它不是用于长度填充和完成步骤,您可以只获取任何消息的散列并使用它来计算该消息的散列,并附加一些额外的数据,就像您可以使用CRC一样.唉,从加密的角度来看,这被认为是一件坏事,并且最终确定步骤特别包含在使其无法实现的过程中.
因此,如果要在消息中间中断散列过程并稍后恢复,则需要在内部状态字符串经过填充和完成阶段之前获取它.
(您可能还需要存储少量附加数据,例如到目前为止处理的块数,以获得正确的长度填充,并且,如果散列在块中间被中断,则任何部分输入块尚未输入混合功能.)
大多数加密库使用存储内部状态的哈希对象实现哈希算法,并允许以任意段提供输入,如下所示(伪代码):
HashFunction hash = new SomeHashFunction(); hash.addInput( data ); // ... hash.addInput( moreData ); BitString output = hash.finalize();通常,即使散列对象可能无法直接访问其内部状态,它们通常也会提供克隆和/或序列化自身的方法.我并不特别熟悉Crypto ++,但一眼就看出它似乎提供了一种
Clone()方法.
PS.如果您对使用加密哈希进行文件完整性验证感兴趣,可能需要查看通用哈希,特别是基于多项式评估的通用哈希函数,如GHASH或Poly1305.这些是非常快速且可并行化的散列函数,它们通常用作经过验证的加密方案的一部分,但也可以单独用作消息验证代码.关于它们的好处是它们不仅可以逐步计算,而且,通过一些聪明的数学,如果对数据中间进行了更改,它们甚至可以逐步更新.它们的主要缺点是,为了防止伪造加密(例如,创建具有相同散列的两个文件),它们需要与密钥一起使用.
2023-02-06 20:06 回答 大爱走钢索的人_738
大爱走钢索的人_738

 京公网安备 11010802041100号
京公网安备 11010802041100号