研究背景
垃圾目标检测作为垃圾分类自动化的一个重要环节,本文将尝试实现该过程。所谓目标检测,简单来讲就是检测图像中的对象是什么以及在哪里的问题,即"目标分类+定位"问题。
YOLO系列模型作为one-stage类目标检测任务的代表算法,凭借其快速、泛化性能好等特性深受研究者喜爱。在前不久,YOLOv5也在GitHub上正式发布,其立即在网上引发了广泛热议。本文将参见官方提供的使用教程,尝试简单利用YOLOv5网络模型在TACO数据集上实现垃圾目标检测任务。
数据集处理
TACO是一个数据正在不断增长的垃圾对象数据集,其以树林、道路和海滩为拍摄背景,目前包含60个类别的垃圾对象,共1500张图像,近5千份标注。该数据集项目参见:https://github.com/pedropro/TACO
一方面,考虑到该数据集文件存放格式和标签格式要符合YOLOv5模型的相关要求;另一方面,也考虑到该数据集中各垃圾类型对象的样本数量极其不均(如图1所示),因此,本文首先需要对数据集进行必要的操作。对于数据集的处理代码可参见Mo项目[1],项目中的_readme.ipynb文件详细给出了相关代码使用的具体操作。
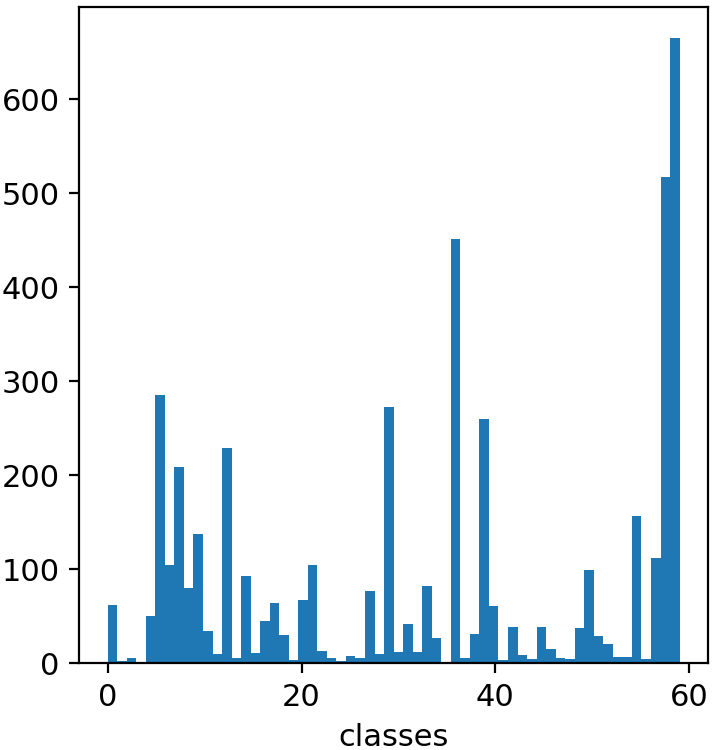
图1 TACO各类别对象的样本数量
对于TACO数据集的处理主要可分为以下两个过程:
(1)由于TACO提供的标签为coco类型(所有信息存放在annotations.json文件中),项目首先需要将相关标签转换为yolo类型。与此同时,考虑到本文仅对相关网络模型进行初探和个人硬件设备的欠缺,该项目仅挑选出满足样本数量大于200的垃圾对象进行相关实验。上述操作的相关代码可以参考博客[1]提供的代码进行修改,该代码可以作为模板用于满足自定义化coco格式转yolo格式需求。
经初步统计,符合要求的垃圾类型(共8类)及其原编号如下所示:
'Clear plastic bottle': 5
'Plastic bottle cap': 7
'Drink can': 12
'Other plastic': 29
'Plastic film': 36
'Other plastic wrapper': 39
'Unlabeled litter': 58
'Cigarette': 59
对于coco格式转yolo格式需求,其主要需完成以下三项任务:
·存储生成的标签和图像分别至两个文件目录中,同时标签和图像的文件命名要求一致
·将目标对象原标签集合递增顺序映射至{0-7}空间
·由于原始标签中位置信息为{top_x, top_y, width, height},项目需要将其转换为{center_x, center_y, width, height}格式,并将其数值进行归一化操作
其核心代码部分如下所示(cocotoyolo.py):
# 将垃圾类型原编号映射至{0-7}空间
label_transfer = {5: 0, 7: 1, 12: 2, 29: 3,
36: 4, 39: 5, 58: 6, 59: 7}
class_num = {} # 记录各类型样本数量
img_ids = data_source.getImgIds()
# 遍历每张图片,对标签进行转换
for index, img_id in tqdm.tqdm(enumerate(img_ids), desc='change .json file to .txt file'):
img_info = data_source.loadImgs(img_id)[0]
# 将含文件夹的路径修改为文件名
save_name = img_info['file_name'].replace('/', '_')
# 移去文件扩展名
file_name = save_name.split('.')[0]
# 获取单张图像的宽和高
height = img_info['height']
width = img_info['width']
# 转换所得txt文件存储路径
save_path = save_base_path + file_name +'.txt'
is_exist =False # 记录图片是否包含目标垃圾类型对象
withopen(save_path, mode='w') as fp:
# 根据图片编号找出垃圾对象的编号集合
annotation_id = data_source.getAnnIds(img_id)
boxes = np.zeros((0, 5))
iflen(annotation_id) ==0: # 集合大小为0
fp.write('')
continue
# 获取coco格式的标签
annotations = data_source.loadAnns(annotation_id)
lines ='' # 记录转换后yolo格式的标签
# 遍历对象标签集
for annotation in annotations:
# 获取垃圾对象的标签
label = coco_labels_inverse[annotation['category_id']]
if label in label_transfer.keys():
# 垃圾类型属于目标垃圾类型则进行格式转换
is_exist =True
box = annotation['bbox']
if box[2] <
# 如果原标签中出现无长或宽数据的情况则跳过
continue
# top_x,top_y,width,height&#61;&#61;>cen_x,cen_y,width,height
box[0] &#61;round((box[0] &#43; box[2] /2) / width, 6)
box[1] &#61;round((box[1] &#43; box[3] /2) / height, 6)
box[2] &#61;round(box[2] / width, 6)
box[3] &#61;round(box[3] / height, 6)
label &#61; label_transfer[label] # 标签映射
if label notin class_num.keys():
class_num[label] &#61;0
class_num[label] &#43;&#61;1
lines &#61; lines &#43;str(label) # 先存储标签
for i in box: # 再存储位置信息
lines &#43;&#61;&#39; &#39;&#43;str(i)
lines &#43;&#61;&#39;\n&#39; # 换行
fp.writelines(lines)
if is_exist:
# 存在目标类型对象&#xff0c;则拷贝图像至指定目录
shutil.copy(&#39;data/{}&#39;.format(img_info[&#39;file_name&#39;]), os.path.join(save_image_path, save_name))
else:
# 不存在则删除所生成的标签文件
os.remove(save_path)
(2)完成标签集的生成后&#xff0c;项目需要对其进行样本划分。首先&#xff0c;项目需要将样本集按训练集使用全部样本&#xff0c;测试集样本占总样本0.1比例的要求(其样本图片的数量分别为1086和109&#xff0c;训练集使用全部样本是考虑到个人硬件设备较差的原因)进行划分。其次&#xff0c;考虑网络模型对样本存储目录的要求&#xff0c;项目需要将相应生成的图像和标签存储至相应的文件夹下&#xff0c;其文件目录格式如图2所示。其实现代码参见Mo项目中的sample.py文件。

图2 数据集存储文件目录
模型配置与训练
YOLOv5项目的下载地址&#xff1a;https://github.com/ultralytics
Mo平台上部署的项目参见同名项目[2]&#xff0c;以下的所有内容可以参考官方教程[2]。该Mo项目的具体操作流程请参见根目录下的_readme.ipynb文件
模型配置
该部分主要涉及相关依赖安装和配置文件设置这两方面内容&#xff0c;接下来&#xff0c;本文将对上述内容进行简要说明。
(1)依赖安装
YOLOv5是由PyTorch深度学习框架搭建而成&#xff0c;因此&#xff0c;我们首先需要在Python中安装PyTorch框架&#xff0c;安装教程可以参见官网的相关内容。此处给出PyTorch最新CPU版本的安装命令。
pip install torch&#61;&#61;1.5.1&#43;cpu torchvision&#61;&#61;0.6.1&#43;cpu -f https://download.pytorch.org/whl/torch_stable.html
除此之外&#xff0c;YOLOv5模型运行还需要安装额外的第三方依赖包。官方已经将其全部放置在requirements.txt文件中。为了安装依赖尽可能不出错&#xff0c;个人对该文件提出以下两点修改意见&#xff1a;
1.本人fork该官方项目时&#xff0c;numpy的版本要求是1.17&#xff0c;但实际安装时会出现一些问题。因此&#xff0c;个人建议将其版本要求修改为1.17.3。
2.该依赖文件所给出的cocoapi.git下载的地址&#xff0c;在实际运行时下载的速度是非常缓慢的&#xff0c;而且在Windows系统下还可能出现异常。因此建议将相应语句用下列语句进行代替&#xff1a;
git&#43;https://github.com/philferriere/cocoapi.git#subdirectory&#61;PythonAPI
(2)配置文件设置
YOLOv5项目主要需要配置如下两个配置文件&#xff1a;
1.data路径下的taco.yaml配置文件(自己创建)。该文件主要配置训练集和测试集存储图片的路径以及对象类型信息。对于标签存储路径的配置&#xff0c;项目会自动根据图片存储路径来确定&#xff0c;这也是为什么我们的数据集文件目录需要符合图2所示要求的原因。该配置文件的内容如下所示。
# train and val datasets (image directory or *.txt file with image paths)
train: taco/images/train/
val: taco/images/test/
# number of classes
nc: 8
# class names
names: [&#39;Clear plastic bottle&#39;, &#39;Plastic bottle cap&#39;,
&#39;Drink can&#39;,
&#39;Other plastic&#39;,
&#39;Plastic film&#39;, &#39;Other plastic wrapper&#39;,
&#39;Unlabeled litter&#39;, &#39;Cigarette&#39;]
2.models路径下与模型配置相关的配置文件编写。根据官方教程[2]&#xff0c;研究者可以直接修改models目录下已存在的 yolov5_.yaml系列文件来进行相关配置。这里&#xff0c;本人修改的是yolov5s.yaml文件(因为该实验使用yolov5s.pt作为模型预训练权重)。个人只要将该文件中nc属性的值修改为与上述taco.yaml的nc属性值一致即可。
模型训练
一方面&#xff0c;由于个人电脑内存相对较小&#xff0c;直接使用官方提供的训练参数设置将会导致内存爆炸而无法工作。因此&#xff0c;该实验不得不通过减少输入图像规模和batch_size值来促使模型进行训练。另一方面&#xff0c;由于个人电脑GPU性能较差&#xff0c;该实验选择直接使用CPU来训练相关模型&#xff0c;因此模型训练速度相对较慢。考虑到上述两方面的限制&#xff0c;本实验模型训练时所涉及的相关参数配置如表1所示&#xff1a;
表1 模型训练相关的参数配置
命令行参数 | 参数含义 | 设置值 |
--img | 统一输入图像规模 | 320 |
--batch | 每次网络训练输入图像的数量 | 4 |
--epochs | 整个数据集参与训练的次数 | 100 |
--data | 数据集配置文件路径 | ./data/taco.yaml |
--cfg | 模型配置文件路径 | ./models/yolov5s.yaml |
--device | 训练的设备(CPU or GPU) | cpu |
--weights | 预训练模型的权重文件 | yolov5s.pt |
模型训练的调用命令如下所示&#xff1a;
python train.py --img320--batch4--epochs100--data ./data/taco.yaml --cfg ./models/yolov5s.yaml --device cpu --weights yolov5s.pt
关于预训练权重的下载&#xff0c;这里就不进行详细介绍&#xff0c;百度一下应该可以找到许多国内下载的资源。在这里&#xff0c;本人在项目根目录下放置了yolov5s的权重文件(yolov5s.pt)以方便研究者训练模型。当然&#xff0c;我们完全可以不使用预训练权重来直接进行模型训练&#xff0c;只要移去上述命令的--weights yolov5s.pt部分即可。
效果展示
根据官方提供的教程&#xff0c;模型训练所生成的各类结果将被自动放置在根目录的runs文件夹下。其中&#xff0c;weights文件夹下将会存放模型训练所生成的效果最好和时间最近的权重文件&#xff0c;我们可以用这些文件完成模型的调用任务&#xff1b;results.txt文件存放着模型训练过程中的各项指标输出&#xff0c;YOLO项目还自动对该输出结果进行了可视化操作&#xff0c;生成了对应的图表图像。本实验各项指标的输出可视化图像如图3所示&#xff0c;上方五张为训练集对应结果&#xff0c;下方五张为测试集对应结果。

图3 模型训练过程各项输出指标的可视化图像
利用detect.py文件我们可以利用生成的模型来检测目标图像中是否存在需要检测 的对象。为了方便起见&#xff0c;我们将生成的模型权重best.pt放置在项目根目录下&#xff0c;将 需要检 测的图像inference/images文件夹下。参考官方文档&#xff0c;我们只需运行如下
代码即可展 示模型目标检测的效果&#xff1a;
python detect.py --weights best.pt --img320--conf0.4
目标图像检测的效果如图4所示&#xff0c;检测生成的图像位于inference/output文件夹 中。其中&#xff0c;batch_1_000048图像中错误检测出了Drink can对象(此处主要与 conf设置值的大小有关&#xff0c;个人可以对其进行适当的调整)。

图4 batch_1_000029(左)和batch_1_000048(右)的检测效果
实验小结
本文主要依托垃圾对象目标检测任务&#xff0c;利用新颖的YOLOv5模型对TACO垃圾对象数据集进行了实验。由于个人硬件设备的不足和时间的限制&#xff0c;参考官方给出的一些输出指标效果图和自行实验所得的图像检测结果&#xff0c;可以看到本文最终所得到的模型的性能其实相对来说不算好(YOLO系列模型本身就是需要跑非常久的时间)。感兴趣地朋友可以尝试增大统一的图像规模、增大batch_size和epoch等方式来提高该模型的目标检测性能。
参考文献
项目地址
[1]TACO&#xff1a;https://momodel.cn/workspace/5f0e734c95faedbb53ab3b26?type&#61;app
[2]yolov5&#xff1a;https://momodel.cn/workspace/5f0e7c929fda75fe7f4b01e9?type&#61;app
主要文献
[1]将COCO中的.json文件转成.txt文件&#xff1a;https://www.jianshu.com/p/8ddd8f3fdf73
[2]Train Custom Data&#xff1a;https://github.com/ultralytics/yolov5/wiki/Train-Custom-Data






![[大整数乘法] java代码实现](https://img1.php1.cn/3cd4a/24c6f/9f3/0133bb25da242824.jpeg)








 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有