工具
系统:win7 64位系统
浏览器:Chrome
Python版本:Python 3.5 64-bit
IDE:JetBrains PyCharm (貌似很多人都用这个)
我把目标瞄准了我们的教务处,这次爬虫的目的是从教务处获取成绩并且把成绩输入Excel表格中保存起来,我们学校教务处的地址是:http://jwc.ecjtu.jx.cn/ ,往常每次我们获取成绩都需要先进入教务处,然后点击成绩查询,输入公共的账号密码进入,最后输入相关信息获取成绩表格,这里登陆不需要验证码省了我一番功夫,这样我们先进入成绩查询系统登陆界面,先看看怎么模拟登陆这个过程,在Chrome浏览器下按F12打开开发者面板:
查看表单数据
这里看到我们需要传递三个参数,分别是:user、pass、Submit,可以很容易的理解这几个单词的字面意思,这样有了思路,我们就可以写出这次代码的第一步:模拟登陆教务处直接上代码:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import requests
url = 'http://jwc.ecjtu.jx.cn/mis_o/login.php'
datas = {'user': 'jwc',
'pass': 'jwc',
'Submit': '%CC%E1%BD%BB'
}
headers = {'Referer': 'http://jwc.ecjtu.jx.cn/mis_o/login.htm',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/52.0.2743.82 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8',
}
sessiOns= requests.session()
respOnse= sessions.post(url, headers=headers, data=datas)
print(response.status_code)代码输出:
200
说明我们模拟登陆成功了,这里用到了Requests模块,还不会使用的可以查看中文文档 ,它给自己的定义是:HTTP for Humans,因为简单易用易上手,我们只需要传入Url地址,构造请求头,传入post方法需要的数据,就可以模拟浏览器登陆了,这里因为有进一步获取成绩的操作所以使用了session来保持连接,这里单看最后的返回码的话我们是成功了的,具体如何还要看下一步操作,接下来:
查看post数据
因为这里就分析输入学号的情况所以其他都为空,这样我们就可以写出查询成绩的代码:
score_healders = {'Connection': 'keep-alive',
'User - Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.82 Safari/537.36',
'Content - Type': 'application / x - www - form - urlencoded',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Content - Length': '69',
'Host': 'jwc.ecjtu.jx.cn',
'Referer': 'http: // jwc.ecjtu.jx.cn / mis_o / main.php',
'Upgrade - Insecure - Requests': '1',
'Accept - Language': 'zh - CN, zh;q = 0.8'
}
score_url = 'http://jwc.ecjtu.jx.cn/mis_o/query.php?start=' + str(
pagenum) + '&job=see&=&Name=&Course=&ClassID=&Term=&StuID=' + num
score_data = {'Name': '',
'StuID': num,
'Course': '',
'Term': '',
'ClassID': '',
'Submit': '%B2%E9%D1%AF'
}
score_respOnse= sessions.post(score_url, data=score_data, headers=score_healders)
cOntent= score_response.content这里解释一下上面的代码,上面的score_url 并不是浏览器上显示的地址,我们要获取真正的地址,在Chrome下右键--查看网页源代码,找到这么一行:
a href=query.php?start=1&job=see&=&Name=&Course=&ClassID=&Term=&StuID=xxxxxxx
这个才是真正的地址,点击这个地址转入的才是真正的界面,因为这里成绩数据较多,所以这里采用了分页显示,这个start=1说明是第一页,这个参数是可变的需要我们传入,还有StuID后面的是我们输入的学号,这样我们就可以拼接出Url地址:
score_url = 'http://jwc.ecjtu.jx.cn/mis_o/query.php?start=' + str(pagenum) + '&job=see&=&Name=&Course=&ClassID=&Term=&StuID=' + num
同样使用Post方法传递数据并获取响应的内容:
score_respOnse= sessions.post(score_url, data=score_data,headers=score_healders) cOntent= score_response.content
这里采用Beautiful Soup 4.2.0来解析返回的响应内容,因为我们要获取的是成绩,这里到教务处成绩查询界面,查看获取到的成绩在网页中是以表格的形式存在:
观察表格的网页源代码:
| 学期 | 学号 | 姓名 | 课程 | 课程要求 | 学分 | 成绩 | 重考一 | 重考二 |
这里拿出第一行举例,虽然我不太懂Html但是从这里可以看出来 这里分解每一列的时候要小心,因为这里表格分成了三页显示,每页最多显示30条数据,这里因为只是收集已经毕业的学生的成绩数据所以不对其他数据量不足的学生成绩的情况做统计,默认收集的都是大四毕业的学生成绩数据。这里采用两个变量 这里查了很多别人的博客都是用正则表达式来分解数据,表示自己的正则写的并不好也尝试了但是没成功,所以无奈选择这种方式,如果有人有测试成功的正则欢迎跟我说一声,我也学习学习。 把数据保存到Excel 因为已经清楚了这个网页保存成绩的具体结构,所以顺着每次循环解析将数据不断加以保存就是了,这里使用 运用到代码中: 最后稍加整合,写成一个方法: 在模拟登陆操作后增加一个判断: 最后在 在PyCharm下按 最终获取结果 至此,大功告成 以上就是Python爬虫模拟登陆教务处并且保存数据到本地的详细内容,更多请关注 第一PHP社区 其它相关文章! 代表的是一行,而 应该是代表这一行中的每一列,这样就好办了,取出每一行然后分解出每一列,打印输出就可以得到我们要的结果: from bs4 import BeautifulSoup
soup = BeautifulSoup(content, 'html.parser')
# 找到每一行
target = soup.findAll('tr')
i和j分别代表行和列:# 注:这里的print单纯是我为了验证结果打印在PyCharm的控制台上而已
i=0, j=0
for tag in target[1:]:
tds = tag.findAll('td')
# 每一次都是从列头开始获取
j = 0
# 学期
semester = str(tds[0].string)
if semester == 'None':
break
else:
print(semester.ljust(6) + '\t\t\t', end='')
# 学号
studentid = tds[1].string
print(studentid.ljust(14) + '\t\t\t', end='')
j += 1
# 姓名
name = tds[2].string
print(name.ljust(3) + '\t\t\t', end='')
j += 1
# 课程
course = tds[3].string
print(course.ljust(20, ' ') + '\t\t\t', end='')
j += 1
# 课程要求
requirments = tds[4].string
print(requirments.ljust(10, ' ') + '\t\t', end='')
j += 1
# 学分
scredit = tds[5].string
print(scredit.ljust(2, ' ') + '\t\t', end='')
j += 1
# 成绩
achievement = tds[6].string
print(achievement.ljust(2) + '\t\t', end='')
j += 1
# 重考一
reexaminef = tds[7].string
print(reexaminef.ljust(2) + '\t\t', end='')
j += 1
# 重考二
reexamines = tds[8].string
print(reexamines.ljust(2) + '\t\t')
j += 1
i += 1xlwt写入数据到Excel,因为xlwt模块打印输出到Excel中的样式宽度偏小,影响观看,所以这里还加入了一个方法去控制打印到Excel表格中的样式:file = xlwt.Workbook(encoding='utf-8')
table = file.add_sheet('achieve')
# 设置Excel样式
def set_style(name, height, bold=False):
style = xlwt.XFStyle() # 初始化样式
fOnt= xlwt.Font() # 为样式创建字体
font.name = name # 'Times New Roman'
font.bold = bold
font.color_index = 4
font.height = height
style.fOnt= font
return stylefor tag in target[1:]:
tds = tag.findAll('td')
j = 0
# 学期
semester = str(tds[0].string)
if semester == 'None':
break
else:
print(semester.ljust(6) + '\t\t\t', end='')
table.write(i, j, semester, set_style('Arial', 220))
# 学号
studentid = tds[1].string
print(studentid.ljust(14) + '\t\t\t', end='')
j += 1
table.write(i, j, studentid, set_style('Arial', 220))
table.col(i).width = 256 * 16
# 姓名
name = tds[2].string
print(name.ljust(3) + '\t\t\t', end='')
j += 1
table.write(i, j, name, set_style('Arial', 220))
# 课程
course = tds[3].string
print(course.ljust(20, ' ') + '\t\t\t', end='')
j += 1
table.write(i, j, course, set_style('Arial', 220))
# 课程要求
requirments = tds[4].string
print(requirments.ljust(10, ' ') + '\t\t', end='')
j += 1
table.write(i, j, requirments, set_style('Arial', 220))
# 学分
scredit = tds[5].string
print(scredit.ljust(2, ' ') + '\t\t', end='')
j += 1
table.write(i, j, scredit, set_style('Arial', 220))
# 成绩
achievement = tds[6].string
print(achievement.ljust(2) + '\t\t', end='')
j += 1
table.write(i, j, achievement, set_style('Arial', 220))
# 重考一
reexaminef = tds[7].string
print(reexaminef.ljust(2) + '\t\t', end='')
j += 1
table.write(i, j, reexaminef, set_style('Arial', 220))
# 重考二
reexamines = tds[8].string
print(reexamines.ljust(2) + '\t\t')
j += 1
table.write(i, j, reexamines, set_style('Arial', 220))
i += 1
file.save('demo.xls')# 获取成绩
# 这里num代表输入的学号,pagenum代表页数,总共76条数据,一页30条所以总共有三页
def getScore(num, pagenum, i, j):
score_healders = {'Connection': 'keep-alive',
'User - Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.82 Safari/537.36',
'Content - Type': 'application / x - www - form - urlencoded',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Content - Length': '69',
'Host': 'jwc.ecjtu.jx.cn',
'Referer': 'http: // jwc.ecjtu.jx.cn / mis_o / main.php',
'Upgrade - Insecure - Requests': '1',
'Accept - Language': 'zh - CN, zh;q = 0.8'
}
score_url = 'http://jwc.ecjtu.jx.cn/mis_o/query.php?start=' + str(
pagenum) + '&job=see&=&Name=&Course=&ClassID=&Term=&StuID=' + num
score_data = {'Name': '',
'StuID': num,
'Course': '',
'Term': '',
'ClassID': '',
'Submit': '%B2%E9%D1%AF'
}
score_respOnse= sessions.post(score_url, data=score_data, headers=score_healders)
# 输出到文本
with open('text.txt', 'wb') as f:
f.write(score_response.content)
cOntent= score_response.content
soup = BeautifulSoup(content, 'html.parser')
target = soup.findAll('tr')
try:
for tag in target[1:]:
tds = tag.findAll('td')
j = 0
# 学期
semester = str(tds[0].string)
if semester == 'None':
break
else:
print(semester.ljust(6) + '\t\t\t', end='')
table.write(i, j, semester, set_style('Arial', 220))
# 学号
studentid = tds[1].string
print(studentid.ljust(14) + '\t\t\t', end='')
j += 1
table.write(i, j, studentid, set_style('Arial', 220))
table.col(i).width = 256 * 16
# 姓名
name = tds[2].string
print(name.ljust(3) + '\t\t\t', end='')
j += 1
table.write(i, j, name, set_style('Arial', 220))
# 课程
course = tds[3].string
print(course.ljust(20, ' ') + '\t\t\t', end='')
j += 1
table.write(i, j, course, set_style('Arial', 220))
# 课程要求
requirments = tds[4].string
print(requirments.ljust(10, ' ') + '\t\t', end='')
j += 1
table.write(i, j, requirments, set_style('Arial', 220))
# 学分
scredit = tds[5].string
print(scredit.ljust(2, ' ') + '\t\t', end='')
j += 1
table.write(i, j, scredit, set_style('Arial', 220))
# 成绩
achievement = tds[6].string
print(achievement.ljust(2) + '\t\t', end='')
j += 1
table.write(i, j, achievement, set_style('Arial', 220))
# 重考一
reexaminef = tds[7].string
print(reexaminef.ljust(2) + '\t\t', end='')
j += 1
table.write(i, j, reexaminef, set_style('Arial', 220))
# 重考二
reexamines = tds[8].string
print(reexamines.ljust(2) + '\t\t')
j += 1
table.write(i, j, reexamines, set_style('Arial', 220))
i += 1
except:
print('出了一点小Bug')
file.save('demo.xls')# 判断是否登陆
def isLogin(num):
return_code = response.status_code
if return_code == 200:
if re.match(r"^\d{14}$", num):
print('请稍等')
else:
print('请输入正确的学号')
return True
else:
return Falsemain中这么调用:if name == 'main':
num = input('请输入你的学号:')
if isLogin(num):
getScore(num, pagenum=0, i=0, j=0)
getScore(num, pagenum=1, i=31, j=0)
getScore(num, pagenum=2, i=62, j=0)alt+shift+x快捷键运行程序:
写下你的评论吧 !
推荐阅读
本文介绍了在Python中使用getpass模块隐藏密码输入的方法,以保护用户的密码不被其他人员看到。同时还提到了在PyCharm中运行该命令无效的问题,需要在terminal中运行。 ...
[详细]
蜡笔小新 2023-12-11 13:46:19
本文讨论了Alink回归预测的不完善问题,指出目前主要针对Python做案例,对其他语言支持不足。同时介绍了pom.xml文件的基本结构和使用方法,以及Maven的相关知识。最后,对Alink回归预测的未来发展提出了期待。 ...
[详细]
蜡笔小新 2023-12-14 14:25:33
文章目录简介HTTP请求过程HTTP状态码含义HTTP头部信息Cookie状态管理HTTP请求方式简介HTTP协议(超文本传输协议)是用于从WWW服务 ...
[详细]
蜡笔小新 2023-10-15 14:59:43
最近在学Python,看了不少资料、视频,对爬虫比较感兴趣,爬过了网页文字、图片、视频。文字就不说了直接从网页上去根据标签分离出来就好了。图片和视频则需要在获取到相应的链接之后取做下载。以下是图片和视 ...
[详细]
蜡笔小新 2023-10-15 09:28:43
 1桌面找到快捷方式双击打开234需要自行注册5看自己喜欢选择喜欢白色选择左边喜欢黑色选择右边67可选如果你对Markdown感兴趣;或者会用就点击install不敢兴趣调到步骤88 ...
[详细]
蜡笔小新 2023-10-14 12:58:26
1桌面找到快捷方式双击打开234需要自行注册5看自己喜欢选择喜欢白色选择左边喜欢黑色选择右边67可选如果你对Markdown感兴趣;或者会用就点击install不敢兴趣调到步骤88 ...
[详细]
蜡笔小新 2023-10-14 12:58:26
 本文介绍了如何通过修改织梦DedeCms源代码来实现全站伪静态,以提高管理和SEO效果。全站伪静态可以避免重复URL的问题,同时通过使用mod_rewrite伪静态模块和.htaccess正则表达式,可以更好地适应搜索引擎的需求。文章还提到了一些相关的技术和工具,如Ubuntu、qt编程、tomcat端口、爬虫、php request根目录等。 ...
[详细]
蜡笔小新 2023-12-14 19:45:47
本文介绍了lua语言中闭包的特性及其在模式匹配、日期处理、编译和模块化等方面的应用。lua中的闭包是严格遵循词法定界的第一类值,函数可以作为变量自由传递,也可以作为参数传递给其他函数。这些特性使得lua语言具有极大的灵活性,为程序开发带来了便利。 ...
[详细]
蜡笔小新 2023-12-14 18:18:21
在说Hibernate映射前,我们先来了解下对象关系映射ORM。ORM的实现思想就是将关系数据库中表的数据映射成对象,以对象的形式展现。这样开发人员就可以把对数据库的操作转化为对 ...
[详细]
蜡笔小新 2023-12-14 10:57:47
本文介绍了在SpringBoot中集成thymeleaf前端模版的配置步骤,包括在application.properties配置文件中添加thymeleaf的配置信息,引入thymeleaf的jar包,以及创建PageController并添加index方法。 ...
[详细]
蜡笔小新 2023-12-14 10:11:46
本文介绍了如何通过修改织梦DedeCms源代码来实现全站伪静态,以提高管理和SEO效果。全站伪静态可以避免重复URL的问题,同时通过使用mod_rewrite伪静态模块和.htaccess正则表达式,可以更好地适应搜索引擎的需求。文章还提到了一些相关的技术和工具,如Ubuntu、qt编程、tomcat端口、爬虫、php request根目录等。 ...
[详细]
蜡笔小新 2023-12-14 19:45:47
本文介绍了lua语言中闭包的特性及其在模式匹配、日期处理、编译和模块化等方面的应用。lua中的闭包是严格遵循词法定界的第一类值,函数可以作为变量自由传递,也可以作为参数传递给其他函数。这些特性使得lua语言具有极大的灵活性,为程序开发带来了便利。 ...
[详细]
蜡笔小新 2023-12-14 18:18:21
在说Hibernate映射前,我们先来了解下对象关系映射ORM。ORM的实现思想就是将关系数据库中表的数据映射成对象,以对象的形式展现。这样开发人员就可以把对数据库的操作转化为对 ...
[详细]
蜡笔小新 2023-12-14 10:57:47
本文介绍了在SpringBoot中集成thymeleaf前端模版的配置步骤,包括在application.properties配置文件中添加thymeleaf的配置信息,引入thymeleaf的jar包,以及创建PageController并添加index方法。 ...
[详细]
蜡笔小新 2023-12-14 10:11:46
 本文介绍了如何使用kaptcha库来实现Java验证码的配置和样式设置,包括pom.xml的依赖配置和web.xml中servlet的配置。 ...
[详细]
蜡笔小新 2023-12-13 13:58:25
本文介绍了如何使用kaptcha库来实现Java验证码的配置和样式设置,包括pom.xml的依赖配置和web.xml中servlet的配置。 ...
[详细]
蜡笔小新 2023-12-13 13:58:25
 本文介绍了使用正则表达式来爬取36Kr网站首页所有新闻的操作步骤和代码示例。通过访问网站、查找关键词、编写代码等步骤,可以获取到网站首页的新闻数据。代码示例使用Python编写,并使用正则表达式来提取所需的数据。详细的操作步骤和代码示例可以参考本文内容。 ...
[详细]
蜡笔小新 2023-12-12 19:16:21
本文介绍了使用cacti监控mssql 2005运行资源情况的操作步骤,包括安装必要的工具和驱动,测试mssql的连接,配置监控脚本等。通过php连接mssql来获取SQL 2005性能计算器的值,实现对mssql的监控。详细的操作步骤和代码请参考附件。 ...
[详细]
蜡笔小新 2023-12-12 13:57:58
本文介绍了使用正则表达式来爬取36Kr网站首页所有新闻的操作步骤和代码示例。通过访问网站、查找关键词、编写代码等步骤,可以获取到网站首页的新闻数据。代码示例使用Python编写,并使用正则表达式来提取所需的数据。详细的操作步骤和代码示例可以参考本文内容。 ...
[详细]
蜡笔小新 2023-12-12 19:16:21
本文介绍了使用cacti监控mssql 2005运行资源情况的操作步骤,包括安装必要的工具和驱动,测试mssql的连接,配置监控脚本等。通过php连接mssql来获取SQL 2005性能计算器的值,实现对mssql的监控。详细的操作步骤和代码请参考附件。 ...
[详细]
蜡笔小新 2023-12-12 13:57:58
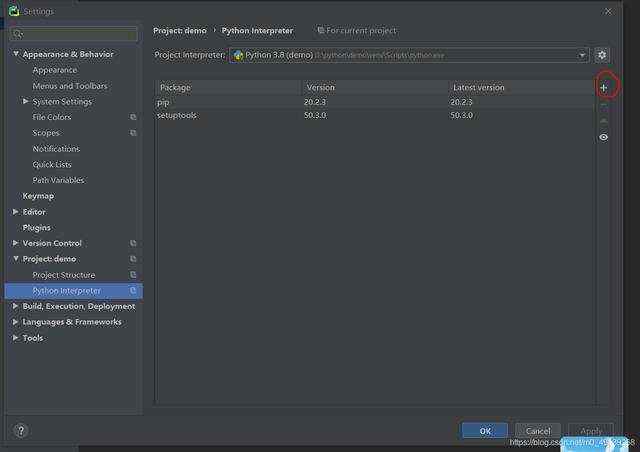 环境准备:事先安装好,pycharm打开File——Settings——Projext——ProjectInterpriter点击加号ÿ ...
[详细]
蜡笔小新 2023-10-15 12:04:37
环境准备:事先安装好,pycharm打开File——Settings——Projext——ProjectInterpriter点击加号ÿ ...
[详细]
蜡笔小新 2023-10-15 12:04:37
 mobiledu2502938737
这个家伙很懒,什么也没留下!
Tags | 热门标签
RankList | 热门文章
mobiledu2502938737
这个家伙很懒,什么也没留下!
Tags | 热门标签
RankList | 热门文章
PHP1.CN | 中国最专业的PHP中文社区 | DevBox开发工具箱 | json解析格式化 |PHP资讯 | PHP教程 | 数据库技术 | 服务器技术 | 前端开发技术 | PHP框架 | 开发工具 | 在线工具
Copyright © 1998 - 2020 PHP1.CN. All Rights Reserved |  京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
