context_re = r'(.*?)'
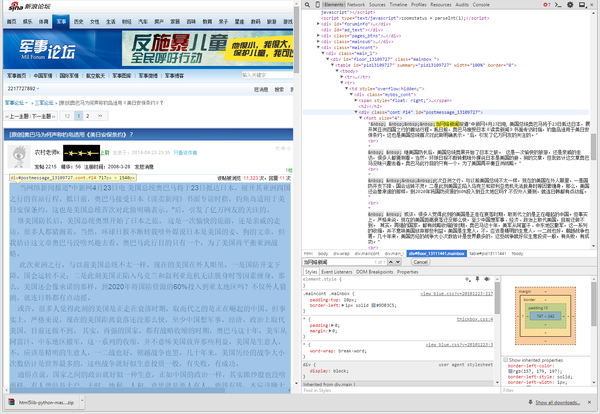
from bs4 import BeautifulSoup import requests response = requests.get("http://club.mil.news.sina.com.cn/thread-666013-1-1.html?retcode=0") #硬点网址 response.encoding = 'gb18030' #中文编码 soup = BeautifulSoup(response.text, 'html.parser') #构建BeautifulSoup对象 ps = soup('p', 'mainbox') #每个楼层 for p in ps: comments = p.find_all('p','cont f14') #每个楼层的正文 with open('Sina_Military_Club.txt','a') as f: f.write('\n'+str(comments)+'\n')
里面的第一个
里面的内容就是原帖的地址,然后再进一步处理)大数据分析就不会了,还请赐教。
import requests from bs4 import BeautifulSoup r = requests.get("http://club.mil.news.sina.com.cn/thread-666013-1-1.html") r.encoding = r.apparent_encoding soup = BeautifulSoup(r.text) result = soup.find(attrs={"class": "cont f14"}) print result.text
# -*- coding:utf-8 -*- import re, requests from bs4 import BeautifulSoup import sys reload(sys) sys.setdefaultencoding('utf-8') url = "http://club.mil.news.sina.com.cn/viewthread.php?tid=666013&extra=page%3D1&page=1" req = requests.get(url) req.encoding = req.apparent_encoding html = req.text soup = BeautifulSoup(html) file = open('sina_club.txt', 'w') x = 1 for tag in soup.find_all('p', attrs = {'class': "cont f14"}): word = tag.get_text() line1 = "---------------评论" + str(x) + "---------------------" + "\n" line2 = word + "\n" line = line1 + line2 x += 1 file.write(line) file.close()










 京公网安备 11010802041100号
京公网安备 11010802041100号