有段时间读取数据的时候都是用下面的命令:
img = cv2.imread(os.path.join(path, file, pic))
img = Image.fromarray(img.astype(np.uint8))
突然有一天突然反应过来为什么要搞这么麻烦,直接使用:
img = Image.open(os.path.join(path, file, pic))
就好了呀
要在pytorch中使用transform等操作就是要用Image.open读入数据才行,这也是为什么上面还要用Image.fromarray转换的原因
补充一点知识:
- 使用 scipy.misc.imread 读取的图片数据是 RGB 格式;
- 使用 cv2.imread 读取的图片数据是 BGR 格式;
- 使用 PIL.Image.open 读取的图片数据是RGB格式;
所以做小波变换的时候就出了问题:
#coding:utf-8 import torch.nn as nn import torch def dwt_init(x): x01 = x[:, :, 0::2, :] / 2 x02 = x[:, :, 1::2, :] / 2 x1 = x01[:, :, :, 0::2] x2 = x02[:, :, :, 0::2] x3 = x01[:, :, :, 1::2] x4 = x02[:, :, :, 1::2] x_LL = x1 + x2 + x3 + x4 x_HL = -x1 - x2 + x3 + x4 x_LH = -x1 + x2 - x3 + x4 x_HH = x1 - x2 - x3 + x4 return torch.cat((x_LL, x_HL, x_LH, x_HH), 1) # 使用哈尔 haar 小波变换来实现二维逆向离散小波 def iwt_init(x): r = 2 in_batch, in_channel, in_height, in_width = x.size() #print([in_batch, in_channel, in_height, in_width]) out_batch, out_channel, out_height, out_width = in_batch, int( in_channel / (r**2)), r * in_height, r * in_width print(out_batch, out_channel, out_height, out_width) x1 = x[:, 0:out_channel, :, :] / 2 x2 = x[:, out_channel:out_channel * 2, :, :] / 2 x3 = x[:, out_channel * 2:out_channel * 3, :, :] / 2 x4 = x[:, out_channel * 3:out_channel * 4, :, :] / 2 print(x1.shape) print(x2.shape) print(x3.shape) print(x4.shape) # h = torch.zeros([out_batch, out_channel, out_height, out_width]).float().cuda() h = torch.zeros([out_batch, out_channel, out_height, out_width]).float() h[:, :, 0::2, 0::2] = x1 - x2 - x3 + x4 h[:, :, 1::2, 0::2] = x1 - x2 + x3 - x4 h[:, :, 0::2, 1::2] = x1 + x2 - x3 - x4 h[:, :, 1::2, 1::2] = x1 + x2 + x3 + x4 return h # 二维离散小波 class DWT(nn.Module): def __init__(self): super(DWT, self).__init__() self.requires_grad = False # 信号处理,非卷积运算,不需要进行梯度求导 def forward(self, x): return dwt_init(x) # 逆向二维离散小波 class IWT(nn.Module): def __init__(self): super(IWT, self).__init__() self.requires_grad = False def forward(self, x): return iwt_init(x) if __name__ == \'__main__\': import os, cv2, torchvision from PIL import Image import numpy as np from torchvision import transforms as trans # img = cv2.imread(\'./1.jpg\') # print(img.shape) # img = Image.fromarray(img.astype(np.uint8)) img = Image.open(\'./1.jpg\') transform = trans.Compose([ trans.ToTensor() ]) img = transform(img).unsqueeze(0) dwt = DWT() change_img_tensor = dwt(img) print(change_img_tensor.shape) for i in range(change_img_tensor.size(1)//3): print(i*3,i*3+3) torchvision.utils.save_image(change_img_tensor[:,i*3:i*3+3:,:], os.path.join(\'./\', \'change_{}.jpg\'.format(i)))
只用第一种方法得到的数据为:
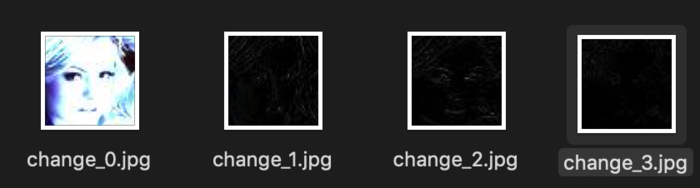
用第二种方法得到的数据是:

这是因为第一种方法读进来的是BGR格式,但是实际要的是下面这种RGB格式,正常情况下存储也是RGB格式
为什么深度学习中普遍用BRG描述图像,而非RGB通道?
因为caffe,作为最早最流行的一批库的代表,用了opencv,而opencv默认通道是bgr的。这是opencv的入门大坑之一,bgr是个历史遗留问题,为了兼容早年的某些硬件。其实你自己训练完全可以用rgb,新库也基本没了bgr还是rgb这个问题,就是切换下顺序。但如果你要用一些老的训练好的模型,就得兼容老模型的bgr。可以进行一下外部转换
比如我之前有处理过一个数据:
from pathlib import Path from config import get_config import argparse from PIL import Image from tqdm import tqdm import mxnet as mx import cv2 import numpy as np def load_mx_rec(rec_path): save_path = rec_path/\'imgs\' if not save_path.exists(): save_path.mkdir() imgrec = mx.recordio.MXIndexedRecordIO(str(rec_path/\'train.idx\'), str(rec_path/\'train.rec\'), \'r\') img_info = imgrec.read_idx(0) header,_ = mx.recordio.unpack(img_info) max_idx = int(header.label[0]) for idx in tqdm(range(1,max_idx)): img_info = imgrec.read_idx(idx) header, img = mx.recordio.unpack_img(img_info) label = int(header.label) #add # img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR) img = Image.fromarray(img) label_path = save_path/str(label) if not label_path.exists(): label_path.mkdir() img.save(label_path/\'{}.jpg\'.format(idx), quality=95) if __name__ == \'__main__\': parser = argparse.ArgumentParser(description=\'for face verification\') parser.add_argument("-r", "--rec_path", help="mxnet record file path",default=\'faces_emore\', type=str) args = parser.parse_args() conf = get_config() rec_path = conf.data_path/args.rec_path load_mx_rec(rec_path) #训练数据在train.idx和train.rec
如果这里我没有添加:
img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)
那么得到的图片颜色就很奇怪:
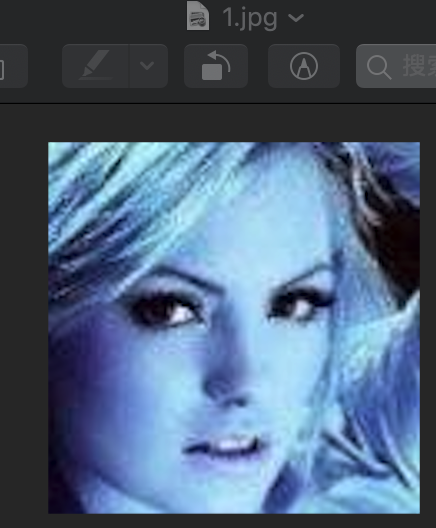
如果我添加了这一个处理后,得到的图像就正常了:
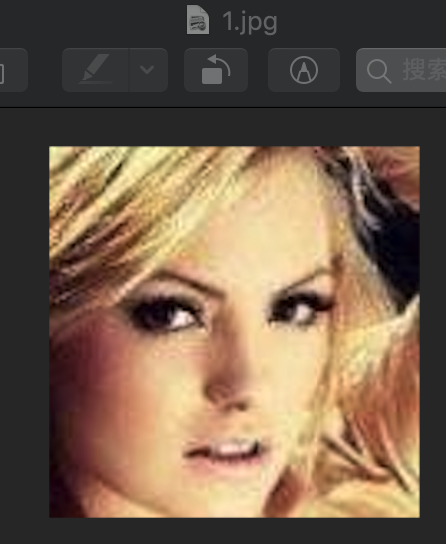
之前有错误写成:
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
但是发现效果是一样的





 京公网安备 11010802041100号
京公网安备 11010802041100号