1. override def start() { 2. super.start() 3. launcherBackend.connect() 4. …… 5. // 封装的命令,该命令发送到Worker节点,并根据获取的资源启动后,相当于 6. // 打开了一个通信通道。 7. val command = Command("org.apache.spark.executor.CoarseGrainedExecutorBackend", 8. args, sc.executorEnvs, classPathEntries ++ testingClassPath, libraryPathEntries, javaOpts) 9. val appUIAddress = sc.ui.map(_.appUIAddress).getOrElse("") 10. val coresPerExecutor = conf.getOption("spark.executor.cores").map(_.toInt) 11. // 通过ApplicationDescription将command封装起来 12. val appDesc = new ApplicationDescription(sc.appName, maxCores, sc.executorMemory, 13. command, appUIAddress, sc.eventLogDir, sc.eventLogCodec, coresPerExecutor) 14. 15. // 构建一个作为应用程序客户端的AppClient实例,并将this设置为该实例的监听 16. // 器,AppClient实例内部会将Executor端的消息转发给this。 17. client = new AppClient(sc.env.rpcEnv, masters, appDesc, this, conf) 18. client.start() 19. launcherBackend.setState(SparkAppHandle.State.SUBMITTED) 20. waitForRegistration() 21. launcherBackend.setState(SparkAppHandle.State.RUNNING) | 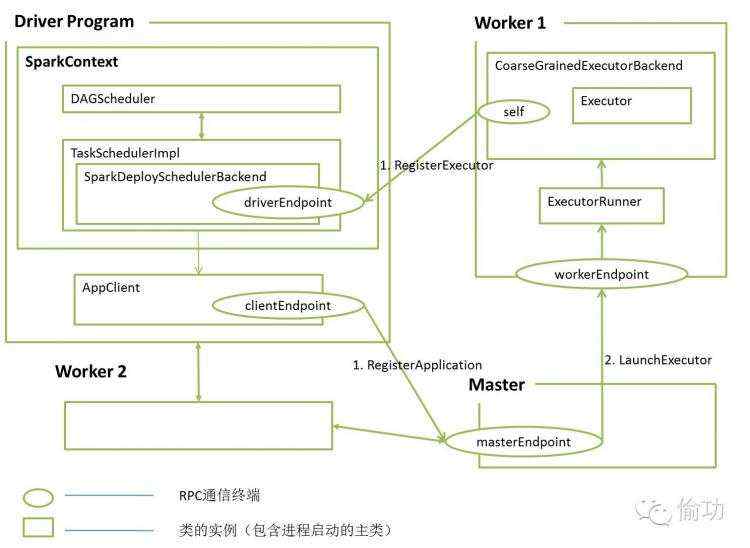






![[翻译]微服务设计模式5. 服务发现服务端服务发现](https://img7.php1.cn/3cdc5/ca23/525/3af55d7cf19345b9.jpeg)


 京公网安备 11010802041100号
京公网安备 11010802041100号