计算一个样本的损失:
整个训练集(或者batch)的损失平均值
目标函数是一个更广泛的概念,在机器学习中,目标函数包含Cost和Regularization(正则项):
方差的概念参考:方差
正则化策略的目的就是降低方差,减小过拟合的发生。
常用的手段有:L1正则化、L2正则化、Dropout、提前终止(早停)、数据扩增。 正则化这个话题比较大,待开一篇文章专门描述。
自信息用于衡量单个事件的不确定性,其公式为:
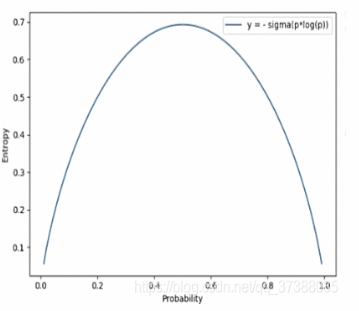
熵指的是信息熵,是自信息的期望。用来描述一个事件的不确定性,一个事件越不确定熵越大。熵是整个概率分布的不确定性,用来描述整个概率分布 伯努利分布的信息熵: 当事件的概率为0.5(如抛硬币)时,其信息熵最大,这也表示事件的不确定性最大,其熵最大值为0.69;如事件“明天太阳从东方生气”(概率极大),其信息熵比较小
相对熵也称为KL散度,相对熵用于衡量两个分布之间的差异,也就是两个分布之间的距离,虽然相对熵可以计算两个分布之间的距离,但是相对熵不是一个距离函数,因为距离函数具有对称性,对称性指的是P到Q的距离等于Q到P的距离,但是相对熵不具备距离函数的对称性。
交叉熵、KL散度、信息熵的关系: 公式中的P是真实的概率分布,也就是训练集中样本的分布,Q是模型输出的分布,因为训练集是固定的,所以H ( P ) 是一个常数,所以交叉熵在优化的时候是优化相对熵。 下面看两个交叉熵具体计算的例子: 参考交叉熵损失函数
交叉熵损失函数经常用于分类问题中,特别是在神经网络做分类问题时,也经常使用交叉熵作为损失函数。此外,由于交叉熵计算中需要输入属于某一类的概率,所以交叉熵几乎每次都和sigmoid(或softmax)函数一起出现。 我们用神经网络最后一层输出的情况,来看一眼整个模型预测、获得损失和学习的流程:
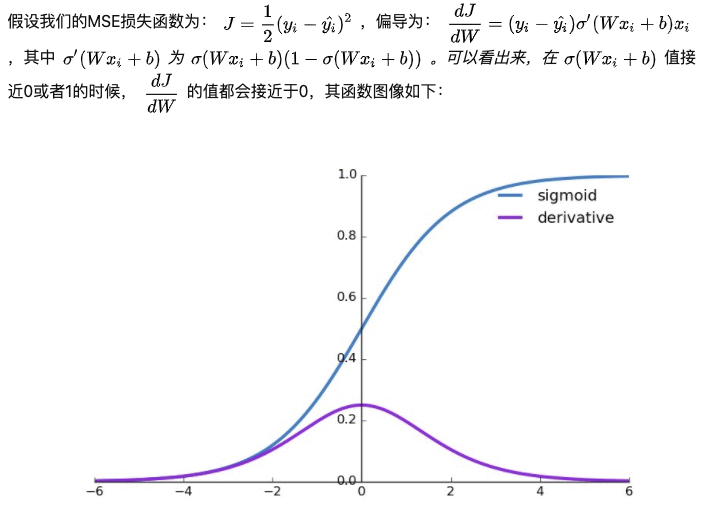
首先来看sigmoid+MSE的缺点:
sigmoid+ CELoss的优点 如公式所示,Loss关于最后一层的w梯度中,si表示sigmoid的输入,yi为label,xi为sigmoid之前的全连接层的输入。 xi -> 全链接层 -> si -> sigmoid层 -> CEloss层。 公式表明,当激活函数层的输出同label差异较大时,L关于w的梯度会较大,从而快速学习。[同生活中“因为明显的犯错可以快速地学习到正确的东西”比较一致]
前面说到,softmax一般配合CEloss一起使用。但是softmax这个操作具体什么含义呢。
在CNN的分类问题中,我们的ground truth是one-hot形式,下面以四分类为例,理想输出应该是(1,0,0,0),或者说(100%,0%,0%,0%),这就是我们想让CNN学到的终极目标。 网络输出的幅值千差万别,输出最大的那一路对应的就是我们需要的分类结果。通常用百分比形式计算分类置信度,最简单的方式就是计算输出占比,这种最直接最最普通的方式,相对于soft的max,在这里我们把它叫做hard的max。 而现在通用的是soft的max,将每个输出x非线性放大到exp(x) 这样做有什么区别呢,看下面的例子:
相同输出特征情况,soft max比hard max更容易达到终极目标one-hot形式,或者说,softmax降低了训练难度,使得多分类问题更容易收敛。同时Softmax鼓励真实目标类别输出比其他类别要大,但并不要求大很多。对于人脸识别的特征映射(feature embedding)来说,Softmax鼓励不同类别的特征分开,但并不鼓励特征分离很多,如上表(5,1,1,1)时loss就已经很小了,此时CNN接近收敛梯度不再下降。
PyTorch中 CrossEntropyLoss 等价于 LogSoftmax + NLLLoss
CrossEntropyLoss 等价于 LogSoftmax + NLLLoss
功能:二分类交叉熵;
BCEWithLogitsLoss就是把Sigmoid-BCELoss合成一步
更多loss参考PyTorch中更多loss说明

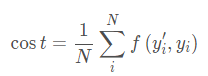
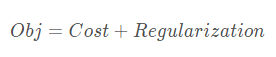
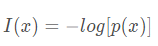
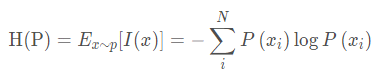
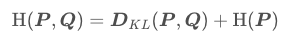


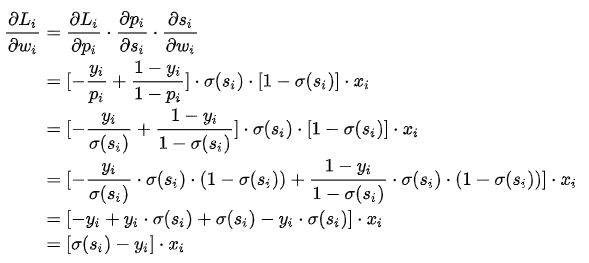
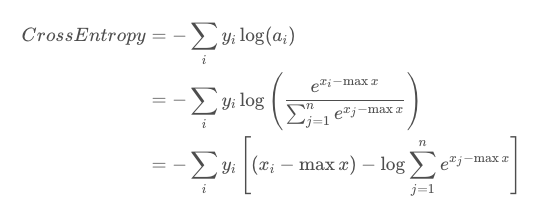

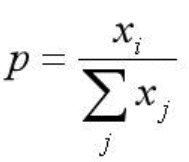
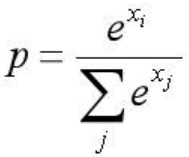











 京公网安备 11010802041100号
京公网安备 11010802041100号