Percona XtraBackup怎样实现全备及增量备份与恢复,相信很多没有经验的人对此束手无策,为此本文总结了问题出现的原因和解决方法,通过这篇文章希望你能解决这个问题。
percona-xtrabackup主要是有两个工具,其中一个是xtrabackup,一个是innobackupex,后者是前者封装后的一个脚本。
在针对MySQL的物理备份工具中,大概是最流行也是最强大的工具了,此外著名的物理备份工具还有官方的mysqlbackup。
xtrabackup只可备份事务表,不能用于备份非事务表,而innobackupex不仅可用于备份事务表,也可以备份非事务表如MyISAM
主要介绍innobakcupex的使用和原理。
本文所用到的版本:
xtrabackup 2.3.7 + MySQL 5.6.30
若MySQL版本为5.7.x,建议使用xtrabackup 2.4.x
〇 xtrabackup可以做的
对InnoDB引擎的表做热备
增量备份
流压缩传输到另外的服务器上
在线移动表
更简单的创建从库
备份时不增加服务器负载
〇 原理
备份及恢复大致涉及三个步骤:备份 -> prepare -> 恢复
备份运行时,工具会记住当时的LSN号,并打开xtrabackup_logfile,然后开始对datafile进行copy,即ibdata1及ibd文件。
复制需要一定的时间,在复制期间,如果文件被修改,工具将监视redo log file并将每一次更变记录下来,保存在xtrabackup_logfile中。
接下来处理非事务表如MyISAM的备份操作,innobackupex通过FLUSH TABLES WITH READ LOCK来阻塞DML。
并在此时获取binlog的position[和GTID](此处我理解为和mysqldump --single-transaction处理方式类似)
在做完非事务表的copy之后,执行UNLOCK TABLES,完成备份,并停止记录xtrabackup_logfile。
接下来就是需要做prepare的过程,该过程类似InnoDB的crash-recovery。
对redo log进行前滚(到数据文件),并将没提交的事务进行回滚操作(rollback),这样便可以保证数据的一致性,所以对于事务表,整个过程是不会影响写操作的。
注:InnoDB、XtraDB、MyISAM是肯定支持的,其他的存储引擎不确定,待测。
〇 权限需求
操作系统:
对datadir需要有rwx的权限。
MySQL:
最小所需要的权限有:
RELOAD
LOCK TABLES(如果加上--no-lock的话可以不要)
REPLICATION CLIENT(为了获得binary log的position)
PROCESS(为了执行show engine innodb status,并且需要查看所有运行的线程)
其他可能需要用到的权限:
CREATE TABLESPACE(如果需要通过5.6+ 的TTS恢复/迁移单个表的话)
SUPER(可能需要在复制环境里启动或者停止slave线程)
CREATE\INSERT\SELECT(对PERCONA_SCHEMA.xtrabackup_history进行操作)
〇 安装
安装超简单(只能在linux上用,不过但这就够了)
https://www.percona.com/downloads/XtraBackup/LATEST/
戳进去选择版本down下来很容易就可以用了。
有RPM包、DEB包、源码包、二进制包。
个人推荐使用二进制包,解压,配置环境变量即可使用,在debian系或RHEL系通用,方便的一比。
源码包的安装,可以参考我这篇博文:
http://blog.itpub.net/29773961/viewspace-1853405/
〇 配置
默认读取my.cnf的选项,读取优先级与MySQL相同。
比如在备份和恢复的时候无需指定datadir等,因为可以读取[mysqld]组下的选项。
同样也可以读取[client]的信息,比如可以将socket,user,password加载到(虽然因为安全因素不建议使用,但是可以这么做)。
当然也可以通过innobackupex --defaults-file=xxxx/my.cnf 去指定将要读取的配置文件。
〇 全备
① 备份:
若加上--no-timestamp,则不会在所指定的目录里生成一个时间戳目录,而是直接放在所指定的目录里,我一般是加的:
innobackupex --user= --password= $basedir [--no-timestamp](当然--user/--password可以直接写作 -u $username -p $password)
在备份的文件夹中,有几个文件值得注意:
xtrabackup_binlog_info记录了binlog的position,若开启了GTID,也会将GTID取出。
在用于备份+binlog恢复或建立slave的场景里十分有用。
xtrabackup_checkpoints记录了此次备份的类型和lsn号的起始值,是否压缩等
xtrabackup_info则记录了备份工具的信息,时间,备份对象(是针对全实例还是某库表),是否是增量,binlog位置等
# cat xtrabackup_binlog_info
binlog.000001 2321 931d11a2-9a8b-11e6-829f-000c298e914c:1-8
# cat xtrabackup_checkpoints
backup_type = full-backuped
from_lsn = 0
to_lsn = 304247338
last_lsn = 304247338
compact = 0
recover_binlog_info = 0
# cat xtrabackup_info
uuid = cfb49b5f-02e8-11e7-94b4-000c298e914c
name =
tool_name = innobackupex
tool_command = --password=... /data/dbbak
tool_version = 2.3.7
ibbackup_version = 2.3.7
server_version = 5.6.30-log
start_time = 2017-03-07 11:47:36
end_time = 2017-03-07 11:47:39
lock_time = 0
binlog_pos = filename 'binlog.000001', position '2321', GTID of the last change '931d11a2-9a8b-11e6-829f-000c298e914c:1-8'
innodb_from_lsn = 0
innodb_to_lsn = 304247338
partial = N
incremental = N
format = file
compact = N
compressed = N
encrypted = N
还有一个backup-my.cnf文件,则记录了备份时可能涉及到的选项参数,比如系统表空间信息,独立undo表空间信息,redo-log信息等:
# cat backup-my.cnf
# This MySQL options file was generated by innobackupex.
# The MySQL server
[mysqld]
innodb_checksum_algorithm=innodb
innodb_log_checksum_algorithm=innodb
innodb_data_file_path=ibdata1:12M:autoextend
innodb_log_files_in_group=2
innodb_log_file_size=50331648
innodb_fast_checksum=false
innodb_page_size=16384
innodb_log_block_size=512
innodb_undo_directory=.
innodb_undo_tablespaces=0
② prepare:
第二步就是prepare,前文也提到,这个过程类似innodb的crash recovery
也可以理解为是“apply”的过程,这里是全备prepare的命令,十分简单
innobackupex --apply-log $basedir
在--apply-log的时候,可以指定--use-memory,增大其值加快速度,若不指定,默认值为100MB。
③ 恢复到datadir:
恢复过程也十分简单(全备和增备都是这一个恢复命令),只需要加上--copy-back参数即可
innobackupex --copy-back $basedir
这样就可以将$basedir的东西恢复到datadir下了,datadir无需指定,将会读取my.cnf获得
默认是需要datadir内为空的(或者没有创建),如果要强制写,则需要加参数: --force-non-empty-directories
〇 增备
增量备份比起全备要复杂一点,本文也想主要介绍如何做增量备份。
用于有的场景,可能不需要每天对数据做全备。
比如有的场景是,每周做一次全备,每天对做一次增量备份,可以节约磁盘空间也可以减少备份时间。
增备的原理是通过对比LSN的信息,来找到被更变的数据,当有了修改操作时,LSN号会改变,和上一次全备的差异LSN号做对比,则可将差异数据备份出来。
整个过程还是分为三个步骤,备份 -> prepare -> 恢复
①增备方法与全备不一样:
innobackupex --user= --password= --incremental $new_dir --incremental-basedir=$basedir
其中--incremental是本次增量备份存放目录
$new_dir是表示将增量备份出来的东西放在哪个目录
--incremental-basedir则表示,针对哪一次备份做增量备份
备份的差异在目录的xtrabackup_checkpoints中查看:
比如:
$basedir中内容:
backup_type = full-prepared
from_lsn = 0
to_lsn = 304247338
last_lsn = 304247338
compact = 0
recover_binlog_info = 0
$new_bkdir中内容:
backup_type = incremental
from_lsn = 304247338
to_lsn = 304250267
last_lsn = 304250267
compact = 0
recover_binlog_info = 0
可以注意一下增备的from_lsn号
大于这个LSN号的页都是被变更过的,这些偏移量,也就是需要被增量备份出去的
②prepare:
prepare过程:
从第一个备份开始(也就是全量)做prepare,再将往后的增量备份依次添加到全量备份中。
注意,此处多了一个参数即--redo-only,该参数是指将已提交的事务应用,未提交的事务回滚。
此外,--incremental-dir也是在之前没有用到过的,这个参数代表需要被合并进去的增量备份目录。
注意,此处多次的增量备份是指:针对上次的增量备份做的增量。
也就是可以理解为:
全备:500GB
第一次增量备份:2GB
第二次增量备份:1GB(针对第一次增量备份的增量数据)
……
第n次
按照备份顺序做prepare,也就是prepare的顺序为:
第一次全备 -> 增量备份1 -> 增量备份2 -> ... -> 增量备份n
第一次全备的prepare:innobackup --apply-log --redo-only $basedir
第二次prepare:innobackup --apply-log --redo-only $basedir --incremental-dir=$new_dir_1(此处的$new_dir_1也就是第一次增量备份)
......
第n次prepare:innobackup --apply-log $basedir --incremental-dir=$new_dir_n(此处的$new_dir_n也就是最近也就是最后一次的增量备份
最后一次增量备份的prepare,不需要指定--redo-only
最后将增量备份和全备进行合并,将未提交的事务回滚,这个操作和全量prepare无异:
innobackup --apply-log $basedir
看起来有点复杂,但没关系,下面会有实验和图解。
③恢复到datadir:
和全量无异,直接copyback就行了
innobackupex --copy-back $basedir
增量备份的prepare有点蛋疼,还是小结一下:
① prepare完备(加上--redo-only)
② prepare每一次增量备份到完备中,需要加上--redo-only,最后一次增量备份的prepare不需要加--redo-only
③ 对生成的最终完备做--apply-log
〇 实验
接下来就是实验……
先建个备份用的用户,给个权限。
mysql> CREATE USER xbackup@localhost IDENTIFIED BY 'back123';
mysql> GRANT RELOAD, PROCESS, LOCK TABLES, REPLICATION CLIENT ON *.* TO xbackup@localhost;
〇 完全备份&恢复
在test.tb里加入测试数据
mysql> CREATE TABLE test.tb(id int primary key, name varchar(16));
Query OK, 0 rows affected (0.07 sec)
mysql> INSERT INTO test.tb VALUES(1,'zhou'),(2,'430'),(3,'YYF'),(4,'ChuaN'),(5,'Faith');
Query OK, 5 rows affected (0.02 sec)
Records: 5 Duplicates: 0 Warnings: 0
创建备份存放目录
$ mkdir -p /data/backup/
指定备份存放位置,开始备份
$ innobackupex -uxbackup -pbackup123 --no-timestamp /data/backup/backup
此处的/data/backup/backup就是全备的目录了。
…………(省略刷屏输出)
xtrabackup: Transaction log of lsn (304289583) to (304290858) was copied.
170321 16:06:11 completed OK!
看到completed OK,表明就真的ok了。
可以看一下这个目录中的内容:
一部分是MySQL下datadir的内容,如库目录,redolog,系统表空间。
一部分是之前也有介绍过的,由备份工具生成的东西:
backup-my.cnf
ibdata1
ib_logfile0
ib_logfile1
mysql
performance_schema
test
xtrabackup_binlog_info
xtrabackup_binlog_pos_innodb
xtrabackup_checkpoints
xtrabackup_info
xtrabackup_logfile
进行prepare
$ innobackupex --apply-log /data/backup/backup
关闭mysqld
$ mysqladmin -uroot -p shutdown
Enter password:
$ ps -ef|grep mysql
root 2991 2438 1 11:08 pts/0 00:00:00 grep mysql
移除datadir:
$ mv /data/mysql_data /data/mysql_data.bk
恢复数据
$ innobackupex --copy-back /data/backup/backup/
修改新datadir的权限
$ chown mysql:mysql -R /data/mysql_data
启动数据库
$ mysqld &
$ ps -ef|grep mysql
root 2712 2438 86 16:35 pts/0 00:00:02 mysqld
root 2714 2438 0 16:35 pts/0 00:00:00 grep mysql
检查test.tb中的内容
$ mysql -e "SELECT * FROM test.tb;"
+----+-------+
| id | name |
+----+-------+
| 1 | zhou |
| 2 | 430 |
| 3 | YYF |
| 4 | ChuaN |
| 5 | Faith |
+----+-------+
至此,完全备份&恢复完成
〇 增量备份&恢复
先来一次全备:
$ innobackupex -uxbackup -pbackup123 --no-timestamp /data/backup/all_backup
修改测试表及数据:(加个字段,改两条数据)
mysql> ALTER TABLE test.tb ADD COLUMN picked varchar(16);
Query OK, 0 rows affected (0.06 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> UPDATE test.tb SET picked='naga' WHERE id=1;
Query OK, 1 row affected (0.04 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> UPDATE test.tb SET picked='TA' WHERE id=2;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
执行第一次增量备份:
$ innobackupex -uxbackup -pbackup123 --no-timestamp --incremental /data/backup/incremental-dir-1 --incremental-basedir=/data/backup/all_backup/
可以再做一次增量备份:
此时有两种增量备份方法:
第一种,总是针对basedir做增量,这个方式恢复起来就特别简单了,只需要将最后一次的增量备份合并到全量备份里,就可以恢复了。
第二种,总是针对上一次的增量,做增量备份。这个方式的恢复,就要逐一合并了,也就是我上述所说看起来有点复杂的增备思路。
反正我是喜欢第一种的,感觉也可以适应绝大多数场景。
我拿word涂了两张图,帮助理解。
第一种:
总是将1月1日的全备作为basedir,所以FROM_LSN号总是5000。
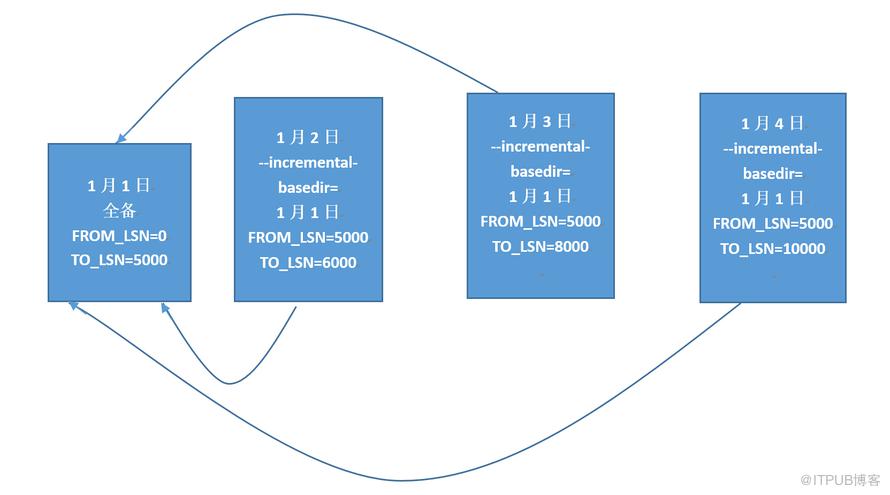
第二种:
总是把上一次(最近一次)的备份作为basedir。

此处介绍第二种:
多次增量备份的方法依旧,只需要修改--incremental-basedir即可:
继续对test.tb做一些修改:
mysql> UPDATE test.tb SET picked='DS' WHERE id=3;
Query OK, 1 row affected (0.04 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> SELECT * FROM test.tb;
+----+-------+--------+
| id | name | picked |
+----+-------+--------+
| 1 | zhou | naga |
| 2 | 430 | TA |
| 3 | YYF | DS |
| 4 | ChuaN | NULL |
| 5 | Faith | NULL |
+----+-------+--------+
5 rows in set (0.01 sec)
针对第一次增量备份/data/backup/incremental-dir-1,做第二次增量备份,将第二次的增量备份放到/data/backup/incremental-dir-2/
$ innobackupex -uxbackup -pbackup123 --no-timestamp --incremental /data/backup/incremental-dir-2/ --incremental-basedir=/data/backup/incremental-dir-1
prepare过程,这个也是增量备份里最蛋疼的过程:
因为总共做了三次备份,所以先做三次prepare:
先对全备做prepare:
$ innobackupex --apply-log --redo-only /data/backup/all_backup/
然后接下来做第一次增量备份的prepare:
$ innobackupex --apply-log --redo-only /data/backup/all_backup/ --incremental-dir=/data/backup/incremental-dir-1
再对第二次的增量备份prepare,注意,第二次的增备是最后一次,所以不需要加上--redo-only参数:
$ innobackupex --apply-log /data/backup/all_backup/ --incremental-dir=/data/backup/incremental-dir-2
最后将两次增量备份和全备做一次合并:
$ innobackupex --apply-log /data/backup/all_backup/
恢复过程,这个和全量恢复没有区别:
停掉mysqld
$ mysqladmin -uroot -p shutdown
$ ps -ef|grep mysql
root 3533 3081 0 17:05 pts/1 00:00:00 grep mysql
移除datadir
$ mv /data/mysql_data /data/mysql_data.bk2
恢复数据
$ innobackupex --copy-back /data/backup/all_backup/
修改新datadir的权限
$ chown mysql:mysql -R /data/mysql_data
启动
$ mysqld &
检查一下,全备和两次增备的内容都已经被恢复回来了,也就是最后一次数据的状态:
$ mysql -uroot -p -e "SELECT * FROM test.tb;"
+----+-------+--------+
| id | name | picked |
+----+-------+--------+
| 1 | zhou | naga |
| 2 | 430 | TA |
| 3 | YYF | DS |
| 4 | ChuaN | NULL |
| 5 | Faith | NULL |
+----+-------+--------+
至此,增量备份&恢复完成
〇 总结一下xtrabackup备份及恢复全过程:
1、备份操作,需要提供具有足够权限的MySQL用户,并且mysqld启动用户需要对datadir有rwx的权限。
2、prepare,将未提交的事务回滚,将已提交的事务写入数据文件。
3、停止mysqld服务
4、mv data/ data_bak_.../
5、copyback回去
6、修改权限新的datadir权限
7、启动服务
当然,上述所有的备份对象,都是针对整个MySQL实例。
看完上述内容,你们掌握Percona XtraBackup怎样实现全备及增量备份与恢复的方法了吗?如果还想学到更多技能或想了解更多相关内容,欢迎关注编程笔记行业资讯频道,感谢各位的阅读!








 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有