( ̄▽ ̄)~*又得半夜修仙了,作为一个爬虫小白,花了3天时间写好的程序,才跑了一个月目标网站就更新了,是有点悲催,还是要只有一天的时间重构。

升级后网站的层次结构并没有太多变化,表面上是国家企业信用信息公示系统 的验证码又升级了。之前是 点按后滑动拼图方式: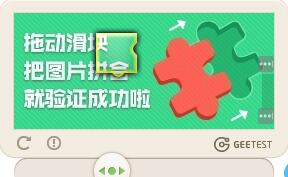
现在的验证码主要是按顺序点击图片汉字验证码,但也不排除会出现以前的点按拖动验证码:
验证码的破解这里就不详细介绍了,需要的可以私信我们一起讨论研究下,详细可参考极验验证码破解-源码+破解手册,极验二代和三代验证码破解的方式基本都是一个套路的东西。
爬虫的过程
- 破解加速乐最新反爬虫机制获取COOKIE
- 传入COOKIE获取 gt 和 challenge 参数 (破解验证码必须的参数)
- 破解验证码
- 带上COOKIE,提交参数跳转下一层
- 抓取数据,这就非常简单了
破解加速乐获取COOKIE
网站更新前是不需要这个步骤的,这次重构代码的时间主要就花在这了。一开始我用 get 方式直接访问 http://www.gsxt.gov.cn/SearchItemCaptcha ,获取 gt 和 challenge 参数 ,但是却返回错误521,于是我发现不仅仅是这个接口,但是发现根本连首页都进不去,返回错误页面403 forbidden,而且细心发现返回的并不是正常的乱码而是一串js代码。
~{}][~~![]]][10].p(T-~~~![]-~~~![]+T),\'%\',[{}+[[], -~{}][~~![]]][10].p(([-~-~~~![]]+~~{}>>-~-~~~![])),\'V\',(+{}+[[], -~{}][~~![]]).p(15),\'L\',(15+[]+[[]][(+[])]),\'t\',([][~~{}]+[]+[]).p(y),\'v\',(-~[]/~~![]+[[], -~{}][~~![]]).p(J),\'%e\'];C(k 8=10;8到这里取COOKIE只传递了一个__jsluid 的COOKIES值。
__jsluid=8d61794e23c2bff4a5c997b272729fba;
Google 了一下,发现这是 加速乐的一个爬虫防护机制)。浏览器第二次请求的时候会带上 __jsluid COOKIEs和JS解密计算出来的一个叫做__jsl_clearance的COOKIEs值,只有这两个COOKIEs验证匹配才认为是合法的访问身份。
这个确实花费了不少时间,知道了问题所在就简单多了,仔细分析上面的js代码就会发现我们要的东西就是这个方法:
eval(y.replace(/\b\w+\b/g,
function(y) {
return x[f(y, z) - 1]
})
接下来就简单,用的是JAVA分析的 ,JAVA的js引擎还是挺好用的。稍微改造下js代码
resHtml = "function getClearance(){" + resHtml+"};";
resHtml = resHtml.replace("", "");
resHtml = resHtml.replace("eval", "return");
resHtml = resHtml.replace("", "");
改造后的代码js:
function getClearance() {
var x = "__jsl_clearance@1515751840@w7ZgszEX@addEventListener@18@Fri@reverse@i@else@l@_phantom@if@captcha@3D@false@Jan@dc@catch@935@var@chips@Expires@Array@COOKIE@charAt@10@function@@D@__phantomas@vHA@while@GMT@4@attachEvent@setTimeout@cd@for@href@Path@challenge@replace@try@1500@6@length@86w@return@onreadystatechange@12@window@TAGGl@location@40@3@@B@document@0@join@DOMContentLoaded@11@e@2".replace(/@*$/, "").split("@"),
y = "k a=r(){w(P.b||P.u){};k B,h=\'1=2.j|10|\';B=n(+[[(+!+[])]+[([-~-~~~![]]+~~{}>>-~-~~~![])]]);k l=[\'Q\',(!{}+[[], -~{}][~~![]]).p(-~[(-~{}<<-~{})]),\'3\',[{}+[[], -~{}][~~![]]][10].p(T-~~~![]-~~~![]+T),\'%\',[{}+[[], -~{}][~~![]]][10].p(([-~-~~~![]]+~~{}>>-~-~~~![])),\'V\',(+{}+[[], -~{}][~~![]]).p(15),\'L\',(15+[]+[[]][(+[])]),\'t\',([][~~{}]+[]+[]).p(y),\'v\',(-~[]/~~![]+[[], -~{}][~~![]]).p(J),\'%e\'];C(k 8=10;8接下来用js引擎执行这段代码。
ScriptEngineManager manager = new ScriptEngineManager();
ScriptEngine engine = manager.getEngineByName("js");
engine.eval(resHtml);
Invocable invocable = (Invocable) engine;
String resJs = (String) invocable.invokeFunction("getClearance");
这样就可以得到这段js原来的样子了,并把没用的东西去掉,得到下面的js,我们会发现dc就是我们需要的东西,具体没用的东西怎么去掉就不贴上来了,只要是有window的代码去掉,会报错;dc就是我们要的东西,模仿上个步骤加上 return dc;就可以了;
var l = function() {
var cd, dc = \'__jsl_clearance=1515751840.935|0|\';
cd = Array( + [[( + !+[])] + [([ - ~ - ~~~ ! []] + ~~ {} >> -~ - ~~~ ! [])]]);
var chips = [\'TAGGl\', (!{} + [[], -~ {}][~~ ! []]).charAt( - ~ [( - ~ {} <<-~ {})]), \'w7ZgszEX\', [{} + [[], -~ {}][~~ ! []]][0].charAt(3 - ~~~ ! [] - ~~~ ! [] + 3), \'%\', [{} + [[], -~ {}][~~ ! []]][0].charAt(([ - ~ - ~~~ ! []] + ~~ {} >> -~ - ~~~ ! [])), \'B\', ( + {} + [[], -~ {}][~~ ! []]).charAt(2), \'86w\', (2 + [] + [[]][( + [])]), \'D\', ([][~~ {}] + [] + []).charAt(4), \'vHA\', ( - ~ [] / ~~ ! [] + [[], -~ {}][~~ ! []]).charAt(6), \'%3D\'];
for (var i = 0; i 直接执行就行了:
engine.eval(resJs);
String learance= (String) invocable.invokeFunction("l");
执行完就是我们要的东西啦:
__jsl_clearance=1515751840.935|0|TAGGltw7ZgszEXf%2BN86wcDOvHAs%3D
将两段COOKIE拼接起来就是最终的COOKIE了:
__jsluid=8d61794e23c2bff4a5c997b272729fba;
__jsl_clearance=1515751840.935|0|TAGGltw7ZgszEXf%2BN86wcDOvHAs%3D;
接下来带上COOKIE访问刚刚的接口(http://www.gsxt.gov.cn/SearchItemCaptcha
),就返回200了,成功
{"challenge":"2f5ce96fd594370c49125a3264166df5","status":"ok","validate":"5be4f4ce721a7c7ad2469925800836a6"}
接下来就简单了。
注意
- 首页返回的JS脚本里面有防止 PhantomJS 的机制:
while (window._phantom || window.__phantomas) {};
当发现是_phantom或者__phantomas后就直接进入死循环了。。
- 最新发现,取上面步骤得到COOKIE访问的后续的页面会报302
解决办法:用得到的COOKIE再次访问,并从response中取set-COOKIE,可以得到:
JSESSIOnID=AFDB40E58D5E6EC434E0584390629C03-n1:-1;
Path=/;
HttpOnlytlb_COOKIE=S172.16.12.67; path=/
再拼接起来才是最终的COOKIE:
__jsluid=8d61794e23c2bff4a5c997b272729fba;
__jsl_clearance=1515751840.935|0|TAGGltw7ZgszEXf%2BN86wcDOvHAs%3D;HttpOnly;secure;
JSESSIOnID=AFDB40E58D5E6EC434E0584390629C03-n1:-1; Path=/;
HttpOnlytlb_COOKIE=S172.16.12.67; path=/
建议将COOKIE缓存,2小时更新一次就可以了










 京公网安备 11010802041100号
京公网安备 11010802041100号