场景
这是原来的存储过程,每次跑批的时候,循环插入数据,导致存储过程运行时间少则半小时,多则一个小时,甚至于造成锁表。
OPEN cur;
read_loop:LOOP
FETCH cur INTO i;
set @ss=select XXXXX;
insert into `hqk`(XX) values(XX)
values
END LOOP;
CLOSE cur;
分析
对于原来的这个存储过程,循环insert肯定造成存储过程时间运行过长,而且随着数据量的扩大,后期运行时间更长。原来的这个存储过程,我们可以看到,循环insert实际上是水平思维或者叫行思维,就是一行一行添加数据。那么如何优化呢,这里有个思路。
将行思维转换,使用列思维。什么意思,也就是我们首先insert关键id信息,然后根据关键id信息进行update操作。这样运行起来就快了很多很多。
更改
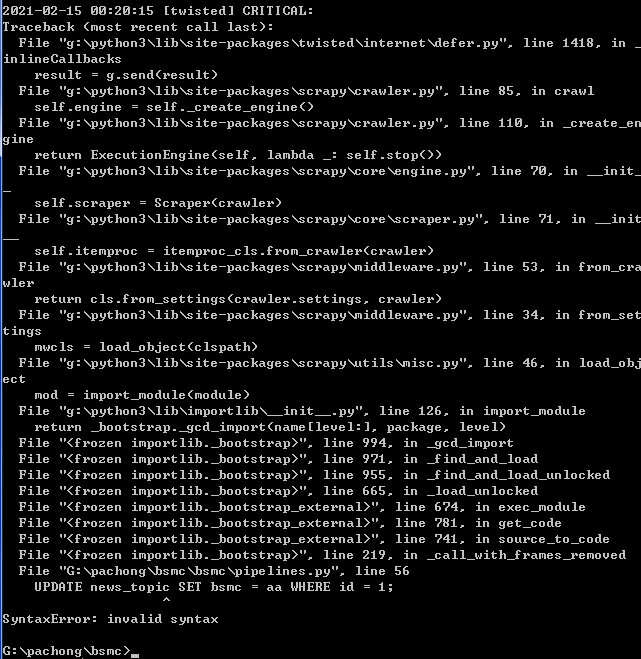
----- 写入需要计算的项目编号和月份,之后剩余字段通过更新填充即可
INSERT INTO bis_report.hf_xm_jyqk(xmid,tt)
SELECT id, b.time_m_v
FROM bis_enrolment.bs_mall a, zh_day_join b
WHERE a.is_del=0 AND a.mall_status IN (2,3,4,5,6,7,8) AND b.time_m_v BETWEEN DATE_ADD(NOW(),INTERVAL -60 month) AND NOW() #现在时间倒










 京公网安备 11010802041100号
京公网安备 11010802041100号