0.引言 随着业务场景的深入和请求量的剧增,单库实现读写越来越趋近瓶颈,于是我们想到搭建主从库,主库负责写,从库负责读,从而实现读写分离,提高查询效率。
但是主从库之间的数据如何同步呢?很明显我们写入数据是只能通过主库操作的,因为我们要求的是主库负责写,从库负责读。我们知道binlog可以实现数据的备份和同步,那么我们是否可以通过它来实现主从同步呢?这就是我们接下来要讨论的了
1. 主从同步原理1.1 基于binlog的主从同步原理 在正式开始讲解实操前,我们需要先了解其原理,否则只能做到知其然,而不知其所以然
什么是bin log? bin log是我们实现主从同步的核心,同时也是我们实现数据备份、数据同步的基础,因此理解bin log是必须的。bin log本身其实就是一个二进制的日志文件,它用于记录数据表结构变化、数据变化。但是不会记录查询等操作,因为查询操作本质上不会引起数据变化。
binlog默认是关闭的,因为其本身的数据记录是会额外消耗性能的,因此我们如果不需要数据备份、同步。那么也不需要开启bin log。
binlog有三种记录模式:
(1)ROW: 行记录形式,会记录每一行的数据变化情况。优点是记得细,能够重现实现数据修改细节。缺点是会产生大量日志,消耗性能
(2)STATEMENT:状态记录形式,会记录每一条执行的SQL,然后通过SQL重放来实现数据同步。优点是节约资源,产生日志量会少很多,缺点是某些情况会导致数据不一致,比如执行的sql中
(3)MIXED:混合模式,一般情况使用STATEMENT,当STATEMENT不能满足的则自动切换为ROW进行记录
我们用一个例子来让大家理解ROW和STATEMENT的区别:
比如我现在执行的操作是 update user set level=5 where age>30。满足age>30的数据有10W条。那么statement模式记录的日志就是update user set level=5 where age>30
看到这里大家可能会觉得,那我就用MIXED呗,但是很多情况下,因为我们要实现主从同步,要保重主从库数据的一致性,必须要求使用ROW,才能完全体现数据变化的日志细节。
在了解了binlog之后,我们再来详细谈谈主从同步的原理细节
(1)主库将数据的变化写入到binlog中
(2)从库定期检测binlog文件是否有发生变化(检测是不需要读取文件详细内容的,可以通过文件最近修改时间和Etag来实现),如果有变化则开启一个IO线程来获取主库binlog数据
(3)同时主库会为每个IO线程启动一个dump线程,用于先IO线程发送二进制事件(也就是binlog日志数据)。发送获取的数据并不会直接给到从库进行重放,而是先放到一个中继日志(relay log)中,然后从库再从中继日志读取数据,进行重发,从而实现数据同步
(4)执行完成后,IO线程和dump线程进行睡眠状态,等待下一次数据同步再被唤醒
想象一下,数据同步过程中为什么需要中继日志,而不是让从库读取后直接重发?
中继日志的存在的目的是什么呢?这里大家发挥出自己的想象,结合以往我们所了解到的中间文件的作用,我们可以首先有一个很常见的作用:
(1)缓冲!让数据先放到中继文件中,攒够一波之后再统一处理,这样能减少IO,提高效率,这是很多中间文件的作用,但是并不是这里中继文件的作用!!!为什么?因为我们要求实时同步,等不了~ 所以攒够一波再处理的概念肯定是不通过的
(2)解耦!这才是中继文件真正的作用。我们利用发证法,假如没有中继日志,那么这个线程很明显要处理一条龙的服务,从读取binlog到重放binlog,这个操作会让这个线程很容易阻塞,因为重发sql时可能会涉及锁表、锁行的操作,不可避免的会造成一些延迟,因此我们读binlog的时候就不能重发,先将binlog实时同步过来,然后再单开一个SQL线程来重放binlog,这才是正确的处理方式。因此我们需要一个日志来帮我们先把同步的binlog记录一下,SQL线程就可以放心的做自己的重放工作,数据同步完成后中继日志会被删除。
了解到这里,相信大家对主从同步的原理已然明了,最终咱们总结下这其中的几个关键词:bin logrelay logio 线程dump 线程sql 线程
但是还有一个问题,咱们还没解决:
主从同步的延迟问题:
(1)主库在记录binlog时是顺序写,效率很高,而从库的SQL线程再重放binlog时,却并不是顺序的,而是随机的。
这里要理解为什么是随机的而不是顺序的?
这里的顺序和随机指的是磁盘IO的读写顺序和随机。因为写入binlog时,是预先申请好磁盘空间的,其空间是连续的,因此写入的binlog在磁盘物理位置上是挨在一起的,即是顺序的。而重发binlog时,相当于我们重新执行sql,其sql操作的数据存放位置基本上是不可能在磁盘中连续的,也就是说起存放位置随机分布,因此我们说是随机的。随机的读写相比较于顺序的读写所需耗费的时间肯定更多
(2)从库SQL线程在重放binlog时,当同时有查询操作出现时,可能会出现锁表、锁行等锁操作,那么就需要等待锁释放的时间,而SQL线程又是单线程的,IO线程依旧在同步binlog,SQL线程这边还在等待着,延迟自然而然就产生了
那么怎么解决延迟问题呢?
首先我们要把握问题发生且我们能够干预的关键点:
从库同步的慢,从而导致了延迟,同步慢的原因:一是同步时有查询操作或者同步本身的操作产生了锁竞争;二是服务器的本身性能问题,我们知道服务器性能越高的,各方面的执行效率肯定越高,基于以上两点,我们提出以下解决方案:
(1)从库使用更好的服务器,这样从库处理的速度更快,则延迟更小
(2)部署一主多从,减少从库的读取压力,提高查询效率,减少锁竞争,从而减少同步延迟
(3)使用缓存数据库,如redis,减少读压力
(4)多主多从,从业务上拆分成多个库,并且将各个库放到不同的服务器上,从而减少单库同步的压力
(5)部署集群,减少压力
以上的解决方案当然都是需要增加服务器成本的,那么有没有从根本上解决这个延迟问题的方案呢?这就是mysql在5.7版本后做出的优化了,也就是我们下面要讨论的MTS主从同步原理
1.2 MTS主从同步原理 MTS:Multi-Threaded Slave,并行复制,实际上早在mysql5.6版本时就有基于库的并行复制,但是5.6版本的基于库的并行复制的性能并不高,当只有一个库时,其性能甚至还不如单线程,因此5.7版本时,做出了优化,推出了真正的并行复制
MTS的核心概念在于多线程并行重放binlog,但是并不是所有的binlog都能并行重放,有些操作可能涉及锁竞争,那么就不能并行执行。
MTS中除了SQL线程,还创建了多个WORK线程,IO线程不断接收bin log,写入到relay log中,SQL线程读取relay log,并且判断哪些事件可以并行回放,哪些只能串行回放。并行回放的会分发给WORK线程并行回放。串行回放的就由SQL线程自己回放。
那么如何判定哪些事件可以并行回放?
通过组提交来实现,即对事务进行分组,我们认为一个组提交的事务都是可以并行回放的,那么怎么判定事务可以处于同一个组呢?那就是看主库中事务执行时,是否能够同时提交成功,或者说同时处于prepare阶段的所有事务,都是可以同时提交的
这里需要大家了解mysql事务两阶段提交的流程,简单来说就是一个事务提交完成是需要经历两个阶段的,事务执行,将数据更新到内容后,会先写入redo log,这时事务处于prepare状态,再写入bin log,然后提交事务,并将redo log标注为commit状态,这样整个事务才算提交完成。经历了prepare,commit两个阶段
只要能同时处于prepare状态的事务,说明事务间是没有锁竞争的,那么就是可以并行执行的,同时也是可以并行回放的。如果有锁竞争的,那么该事务肯定要等待竞争事务先执行完,释放锁后才能执行,也就不可能同时处于prepare状态
所以我们接下来要解决的问题就是:
1、如何知道哪些事务处于prepare状态?
mysql5.7引入了两个变量
(1)sequence_number
(2)last_committed
这两个变量都会记录到bin log中,并且其作用域是文件范围内,也就是说换了一个bin log文件,其值就会从0开始计算。于是乎通过last_committed我们也就知道了哪些事务是同一组的。
2、在binlog中如何标注哪些事务是同一组的?
其实我们上面已经讲到了,是通过last_committed信息来标注,但这里我们要拓展一下,mysql5.7中将sequence_number和last_committed信息属于组提交信息,组提交信息是存放到GTID事件中的,每个事务会有自己的GTID事件。
GTID默认是关闭的,如果关闭时会讲组提交信息存放到匿名GTID事件中(Anonymous_Gtid),如果开启了,就会存储到每个事务自己的GTID事件中,每个事务执行前都会添加一个GTID事件,用于记录当前的全局事务ID
MTS并发复制流程
在了解了并发复制的原理后,我们再来整体的梳理一遍其流程:
(1)主库将数据的变化写入到binlog中
(2)从库定期检测binlog文件是否有发生变化,如果有变化则开启一个IO线程来获取主库binlog数据
(3)同时主库会为每个IO线程启动一个dump线程,用于先IO线程发送二进制事件(也就是binlog日志数据)。发送获取的数据并不会直接给到从库进行重放,而是先放到一个中继日志(relay log)中
(4)从库的SQL线程从relay log中读取事务后,会获取该事务的组信息,拿到sequence_number和last_committed
(5)从库会记录已经执行了的事务的sequence_number的最小值,将其存放到low water mark变量中,简称lwm
(6)lwm与取出事务的last_committed比较,如果last_committed比lwm更小,说明取出事务与当前执行组为同组(本组事务的sequence_number的最小值肯定大于last_committed)。则SQL线程会找到一个空闲的WORK线程,如果有空闲的,就会直接重放这个事务,如果没有空闲的,SQL线程就会处于等待状态,直到有一个空闲的WORK线程为止。
(7)如果last_committed等于大于lwm,则说明取出事务与当前执行组不是同一组,则取出事务需要等待。
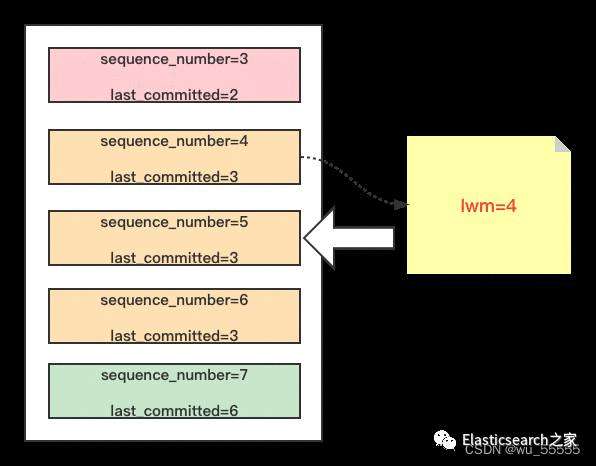
如下图所示,当获取到事务4时,因为已经执行的事务的最小sequence_number是3,则lwm是3 而事务4的last_committed为3,是等于lwm的,则知道事务3和事务4不是一组
当继续执行到事务5时,因为已经执行过事务4了,则lwm=4,而事务5的last_committed=3,小于lwm,则事务5与事务4同组,可以并发复制
2. 主从同步实操 了解完主从同步的原理后,我们来实际演示下配置流程
2.1 环境准备 首先这里需要准备两台mysql服务器,一台作为主库,一台作为从库,我这里选用mysql8.0。并且创建一些数据库和表,添加一些数据进去作为同步测试
2.2 实操 1、因为是基于binlog的,需要在主从库都开启binlog,并且开启主库的GTID,修改主库配置文件
修改内容
2、重启主库
3、查询binlog是否开启成功,登陆主库执行
4、给连接主库进行数据同步的账号赋权,登陆主mysql执行:
5、修改从库mysql配置文件
修改内容
6、重启从库
7、声明主库,登陆从库执行:
8、查看从库状态
# 表格形式输出,适合在数据库连接工具中使用 show slave status ; # 行形式输出,适合在命令行窗口中使用 show slave status\G ;
如图所示无报错即可
9、修改主库数据,任意修改了一条数据
10、查看从库对应的表数据
同步成功!!
总结 本期的分享就到此结束了,一定要亲自动手实操试试,只有自己尝试,才会发现更多的问题,才能掌握的更加牢靠
文中配置文件源码及常见报错可点击`阅读原文`找到
E l a s t i c 开 源 社 区
长 按 加 关 注 , 学 习 不 迷 路



















 京公网安备 11010802041100号
京公网安备 11010802041100号