public enum QueryOperation
{
STREQ = 0, // # 查询条件: 表示与操作对象的文字内容完全相同(=)
STRINC = 1, // # 查询条件: 表示含有操作对象文字的内容(LIKE ‘%文字%')
STRBW = 2, // # 查询条件: 表示以操作对象的文字行列开始(LIKE ‘文字%')
STREW = 3, // # 查询条件: 表示到操作对象的文字行列结束(LIKE ‘%文字')
STRAND = 4, // # 查询条件: 表示包含操作对象的文字行列中右逗号分开部分的字段的全部(name LIKE ‘%文字㈠%' AND name LIKE ‘%文字㈡%')
STROR = 5, // # 查询条件: 表示包含操作对象文字段中逗号分开部分的其中一部分(name LIKE ‘%文字㈠%' OR name LIKE ‘%文字㈡%')
STROREQ = 6, // # 查询条件: 表示与操作对象文字段中逗号分开部分的其中某部分完全相同( name = ‘文字㈠' OR name =‘文字㈡')
STRRX = 7, // # 查询条件: 表与与常规表达式匹配
NUMEQ = 8, // # 查询条件: 表示等于操作对象的数值(=)
NUMGT = 9, // # 查询条件: 表示比操作对象的数值要大(>)
NUMGE = 10, // # 查询条件: 表大于或等于操作对象的数值(>=)
NUMLT = 11, // # 查询条件: 表示比操作对象的数值要小(<)
NUMLE = 12, // # 查询条件: 表示小于或等于操作对象的数值(<=)
NUMBT = 13, // # 查询条件: 表示其大小处于操作对象文字段中被逗号分开的两个数值的中间(between 100 and 200)
NUMOREQ = 14, // # 查询条件: 表示其大小处于操作对象文字段中被逗号分开的两个数值的中间(between 100 and 200)
NEGATE = 1 <<24, // # 查询条件: 负标志negation flag
NOIDX = 1 <<25 // # 查询条件: 非索引标志
} 查询指定主键(如本例中的olid,效率最高)
代码如下:
var qrecords = TokyoTyrantService.GetColumns(pool, new string[]{"1", "2", "3"});
foreach (string key in qrecords.Keys)
{
var column = qrecords[key];
} 更新操作:
因为TC的TCT结构没有提供直接更新记录中某一字段的功能,所以只能全部取出相关记录的所有字段,然后再更新全部字段(这种做法的效率不高,但在MONGODB中是可以更新部分字段)。所以要组合使用查询和创建操作中的语法,即选查出相应记录,然后再使用PutColumns方法更新该记录,形式如下:
代码如下:
var qrecords = TokyoTyrantService.QueryRecords(TTPool.GetInstance(), new Query().NumberEquals("olid", 1));
foreach (var k in qrecords.Keys)
{
var column = qrecords[k];
...数据绑定操作
TokyoTyrantService.PutColumns(TTPool.GetInstance(), column["olid"], columns, true);//column["olid"]为主键,类似数据库里的主键,以其为查询条件,速度最快
} 删除操作
该操作有两种执行方法,一种是选查询出符合条件的记录,然后再删除(依次删除),一种是直接给定要删除的主键直接删除(效率比前者高)。第一种(可以针对不用字段进行查询,并将相应结果的主键做了删除依据)
代码如下:
var qrecords = TokyoTyrantService.QueryRecords(TTPool.GetInstance(), new Query().NumberEquals("userid", 1));
foreach (var k in qrecords.Keys)
{
var column = qrecords[k];
...数据绑定操作
TokyoTyrantService.Delete(TTPool.GetInstance(), column["olid"]);//column["olid"]为主键,类似数据库里的主键
}
第二种(删除olid为1或2或3或4的键值记录,只能删除以主键为条件的记录):
TokyoTyrantService.DeleteMultiple(pool, new string[] { "1", "2", "3", "4" });
创建索引
TC中支持几种类型的字段索引如下(经常用的是数值型和字符型):
代码如下:
///
public enum IndexOption : int
{
LEXICAL = 0, // # 文本型索引
DECIMAL = 1, // # 数值型索引
TOKEN = 2, // # 标记倒排索引.
QGRAM = 3, // #QGram倒排索引.
OPT = 9998, // # 9998, 对索引优化
VOID = 9999, // # 9999, 移除索引.
KEEP = 1 <<24 // # 16777216, 保持已有索引.
}
比如在线表中经常用的字段索引设置如下:
代码如下:
TokyoTyrantService.SetIndex(pool, "olid", IndexOption.DECIMAL);
TokyoTyrantService.SetIndex(pool, "userid", IndexOption.DECIMAL);
TokyoTyrantService.SetIndex(pool, "password", IndexOption.LEXICAL);
TokyoTyrantService.SetIndex(pool, "ip", IndexOption.LEXICAL);
TokyoTyrantService.SetIndex(pool, "forumid", IndexOption.DECIMAL);
TokyoTyrantService.SetIndex(pool, "lastupdatetime", IndexOption.DECIMAL); 3.其它常用操作
代码如下:
LimitTo(int max, int skip):类似于MYSQL中的LIMIT方法,其中max如同mssql中的TOP,而skip则表示跳过多少条记录(类似LINQ中的那个Skip方法)
Vanish(TcpClientIOPool pool);清空所有记录
QueryRecordsCount(TcpClientIOPool pool, Query query)//查询指定条件的记录数
GetRecordCount(TcpClientIOPool pool)//返回当前表中的记录总数
GetDatabaseSize(TcpClientIOPool pool);//获取数据库(表)信息
IteratorNext(TcpClientIOPool pool)//一个迭代器,用于遍历所有记录
4.因为其兼容Memcached,所以提供方法支持(键/值对)
代码如下:
Put(TcpClientIOPool pool, string key, string value, bool overwrite)//该操作方法将不像Put那样获取服务器端返回的信息
PutFast(TcpClientIOPool pool, string key, string value)//快速存储键值对(不再获取服务端返回信息). 如键值已存在则将被覆盖
PutMultiple(TcpClientIOPool pool, IDictionary
items) //一次添加多值 更多相关Discuz论坛的内容来自#
推荐阅读
本文详细介绍了SQL日志收缩的方法,包括截断日志和删除不需要的旧日志记录。通过备份日志和使用DBCC SHRINKFILE命令可以实现日志的收缩。同时,还介绍了截断日志的原理和注意事项,包括不能截断事务日志的活动部分和MinLSN的确定方法。通过本文的方法,可以有效减小逻辑日志的大小,提高数据库的性能。 ...
[详细]
蜡笔小新 2023-12-14 18:23:25
在说Hibernate映射前,我们先来了解下对象关系映射ORM。ORM的实现思想就是将关系数据库中表的数据映射成对象,以对象的形式展现。这样开发人员就可以把对数据库的操作转化为对 ...
[详细]
蜡笔小新 2023-12-14 10:57:47
使用Ubuntu中的Python获取浏览器历史记录原文: ...
[详细]
蜡笔小新 2023-12-14 08:57:59
本文介绍了Oracle数据库中tnsnames.ora文件的作用和配置方法。tnsnames.ora文件在数据库启动过程中会被读取,用于解析LOCAL_LISTENER,并且与侦听无关。文章还提供了配置LOCAL_LISTENER和1522端口的示例,并展示了listener.ora文件的内容。 ...
[详细]
蜡笔小新 2023-12-14 07:44:06
本文介绍了通过ABAP开发往外网发邮件的需求,并提供了配置和代码整理的资料。其中包括了配置SAP邮件服务器的步骤和ABAP写发送邮件代码的过程。通过RZ10配置参数和icm/server_port_1的设定,可以实现向Sap User和外部邮件发送邮件的功能。希望对需要的开发人员有帮助。摘要长度:184字。 ...
[详细]
蜡笔小新 2023-12-13 15:50:17
本文介绍了一个在线急等问题解决方法,即如何统计数据库中某个字段下的所有数据,并将结果显示在文本框里。作者提到了自己是一个菜鸟,希望能够得到帮助。作者使用的是ACCESS数据库,并且给出了一个例子,希望得到的结果是560。作者还提到自己已经尝试了使用"select sum(字段2) from 表名"的语句,得到的结果是650,但不知道如何得到560。希望能够得到解决方案。 ...
[详细]
蜡笔小新 2023-12-13 15:15:30
本文讨论了在数据库打开和关闭状态下,重新命名或移动数据文件和日志文件的情况。针对性能和维护原因,需要将数据库文件移动到不同的磁盘上或重新分配到新的磁盘上的情况,以及在操作系统级别移动或重命名数据文件但未在数据库层进行重命名导致报错的情况。通过三个方面进行讨论。 ...
[详细]
蜡笔小新 2023-12-13 13:02:24
本文描述了mysql-cluster集群sql节点高可用keepalived的故障处理过程,包括故障发生时间、故障描述、故障分析等内容。根据keepalived的日志分析,发现bogus VRRP packet received on eth0 !!!等错误信息,进而导致vip地址失效,使得mysql-cluster的api无法访问。针对这个问题,本文提供了相应的解决方案。 ...
[详细]
蜡笔小新 2023-12-12 19:20:50
本文介绍了iOS数据库Sqlite的SQL语句分类和常见约束关键字。SQL语句分为DDL、DML和DQL三种类型,其中DDL语句用于定义、删除和修改数据表,关键字包括create、drop和alter。常见约束关键字包括if not exists、if exists、primary key、autoincrement、not null和default。此外,还介绍了常见的数据库数据类型,包括integer、text和real。 ...
[详细]
蜡笔小新 2023-12-12 18:42:03
本文介绍了Oracle seg,V$TEMPSEG_USAGE与Oracle排序之间的关系,V$TEMPSEG_USAGE是V_$SORT_USAGE的同义词,通过查询dba_objects和dba_synonyms视图可以了解到它们的详细信息。同时,还探讨了V$TEMPSEG_USAGE的使用方法。 ...
[详细]
蜡笔小新 2023-12-12 17:57:15
本文介绍了Oracle存储过程的基本语法和写法示例,同时还介绍了已命名的系统异常的产生原因。 ...
[详细]
蜡笔小新 2023-12-11 15:10:15
本文分析了Wince程序内存和存储内存的分布及作用。Wince内存包括系统内存、对象存储和程序内存,其中系统内存占用了一部分SDRAM,而剩下的30M为程序内存和存储内存。对象存储是嵌入式wince操作系统中的一个新概念,常用于消费电子设备中。此外,文章还介绍了主电源和后备电池在操作系统中的作用。 ...
[详细]
蜡笔小新 2023-12-10 16:21:27
本文介绍了MySQL数据库锁机制及其应用。数据库锁是计算机协调多个进程或线程并发访问某一资源的机制,在数据库中,数据是一种供许多用户共享的资源,如何保证数据并发访问的一致性和有效性是数据库必须解决的问题。MySQL的锁机制相对简单,不同的存储引擎支持不同的锁机制,主要包括表级锁、行级锁和页面锁。本文详细介绍了MySQL表级锁的锁模式和特点,以及行级锁和页面锁的特点和应用场景。同时还讨论了锁冲突对数据库并发访问性能的影响。 ...
[详细]
蜡笔小新 2023-12-10 15:54:07
本文介绍了解决nginx启动报错epoll_wait() reported that client prematurely closed connection的方法,包括检查location配置是否正确、pass_proxy是否需要加“/”等。同时,还介绍了修改nginx的error.log日志级别为debug,以便查看详细日志信息。 ...
[详细]
蜡笔小新 2023-12-12 13:19:04
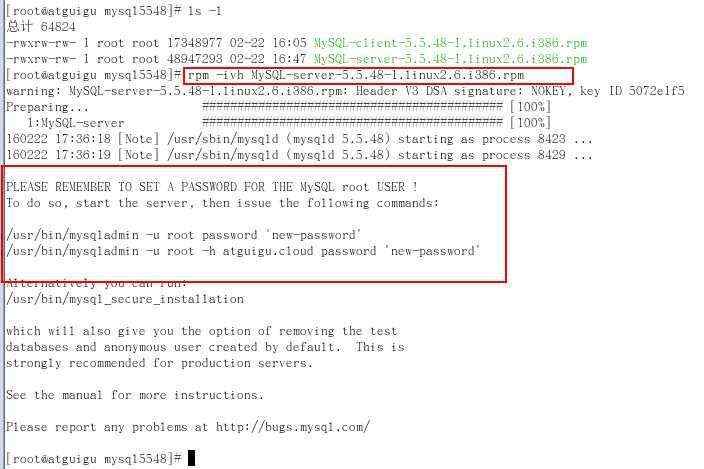
本文介绍了centos安装Mysql的两种方式:rpm方式和绿色方式安装,详细介绍了安装所需的软件包以及安装过程中的注意事项,包括检查是否安装成功的方法。通过本文,读者可以了解到在centos系统上如何正确安装Mysql。 ...
[详细]
蜡笔小新 2023-12-11 07:30:47





 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有