作者:小甜甜龌龊的华丽 | 来源:互联网 | 2023-06-07 19:59
IEEEGEOSCIENCEANDREMOTESENSINGLETTERSS.K.Roy,G.Krishna,S.R.Dubey,B.B.ChaudhuriHybridSN:Ex
IEEE GEOSCIENCE AND REMOTE SENSING LETTERS
S. K. Roy, G. Krishna, S. R. Dubey, B. B. Chaudhuri HybridSN: Exploring 3-D–2-D CNN Feature Hierarchy for Hyperspectral Image Classification, IEEE GRSL 2020
摘要:高光谱图像分类在遥感图像分析领域应用广泛。高光谱图像包括众多波段影像。卷积神经网络(CNN)作为深度学习的一种适合图像数据处理。近来,将CNN用于高光谱图像分类的研究比较常见。这些方法大多基于2D-CNN。另一方面,高光谱图像分类高度依赖于空间和光谱信息。很少采用3D-CNN原因在于计算的复杂度。本文采用混合卷积神经网络(HybridSN)进行高光谱图像分类。通常来说,混合卷积神经网络先是空间2D-CNN,接着3D-CNN。3D-CNN发挥出众多光谱联合空间的特征。3D-CNN上的2D-CNN能学习到更多的抽象空间表达。而且,混合CNN比单独使用3D-CNN减少了模型的复杂度。为了测试这种混合CNN方法的表现,在Indian Pines、University of Pavia,Salinas Scene这几个遥感数据集上进行实验。实验结果对比了state-of-the art hand-crafted端到端深度学习方法。混合CNN在高光谱图像分类上具有令人满意的性能。源代码可以在https://github.com/gokriznastic/HybridSN获得。
索引:2D-CNN,3D-CNN,深度学习,混合CNN,高光谱图像分类,遥感,光谱-空间。
I.Introduction
高光谱图像分类在现实生活中具有潜在的重要应用价值。高光谱图像具有众多波段影像,庞大的数据量给数据分析带来挑战。不同波段的光谱和空间信息表达出感兴趣区域有价值的信息。近来,Camps-Valls 对高光谱图像分类进展进行了研究。对于高光谱图像分类,有两个方向,一是人工提取特征的技术,另一个是基于学习的特征提取技术。
基于人工提取特征的方法有:Yang和Qian提出一种基于局部自适应字典的联合协作表示法。其减少了无用像元的不利影响,改善了高光谱图像分类效果。Fang等人利用局部协方差矩阵对不同光谱波段间的关系进行编码。他们采用支持向量机进行训练和分类。通过一个复合内核将空谱信息联合进行高光谱图像分类。Li等人将多特征结合起来用于高光谱场景分类。其他基于人工提取的方法还有联合系数模型、不连续保持松弛、基于玻尔兹曼熵波段选择、稀疏自表示、融合相关系数和稀疏表示,多尺度超级像素和引导过滤器等等。
近来,卷积神经网络由于其超越人工提取特征的性能开始流行。CNN在视觉信息处理领域展示出优越的表现,如图像分类、目标检测、语义分割、医学诊断、深度估计,人脸反扫。最近几年,高光谱图像分类的深度学习也取得了巨大进展。一种双通道的网络(DPN)结合了残差网络和密集卷积网络应用在高光谱图像分类。Yu等人提出一个贪婪分层方法用于非监督训练。Li等人提出一种像素块配对数据扩充的技术用于高光谱图像分类。Song等人提出一种深度特征融合的网络,Cheng等人将off-the-shelfCNN模型用于高光谱图像分类。总体上,学者们提取到了更深层的空间特征,进行了支持向量集的训练和分类。用于高光谱图像分类的低功耗的硬件设备也被开发出来。Chen等用3D-CNN进行高光谱图像分类的特征提取。Zhong等提出光谱-空间残差网络(SSRN)。剩余的SSRN块使用identity mapping连接每个3D卷积层。Mou等研究剩余的卷积-反卷积网络,在高光谱图像分类上使用了非监督分类方法。Paolett等提出了深度金字塔残差网络(DPRN)用于高光谱数据,他最近提出了空谱胶囊网络。Fang用深度哈希神经网络用于高光谱特征提取。
从以上文献中可以看出只是用2D-CNN或者3D-CNN都有一些缺点,如缺失通道间的关系信息或模型太复杂。这些都使得高光谱图像的分类准确率受到影响。主要原因在于高光谱数据大量的数据和光谱维数。单独使用2D-CNN不能在光谱维数上提取出区分性好的特征图。类似,3D-CNN计算更复杂单独使用时,在这些光谱波段同样纹理信息上表现不佳。这就是本文使用一种混合CNN的理由,可以克服以上模型的缺点。在该模型中,3D-CNN和2D-CNN层的集合可以使空间特征和光谱特征充分利用,实现最大程度的准确率。
在Section II中本文介绍这种混合CNN。在III中对实验和分析进行介绍;在IV中重点介绍结论。
II混合CNN模型
将高光谱数据立方体表示成I,代表原始输入,M代表图像宽度,N是图像高度,D为光谱波段数。数据I中的像元具有光谱信息和地物标签。然而,高光谱像元表现出的混合地物导致的类内变异性和类间相似性给分类带来巨大挑战。首先为了消除光谱冗余,将PCA主成分分析法用于光谱数据。PCA可将原始光谱数据波段数从D降到B,同时保持相同的空间尺寸,M仍为宽度,N仍为高度。我们仅仅减少了波段数,保持了同样的空间信息,这对于识别地物非常重要。现在我们通过PCA获得数据X,具有M的图像宽度,N的图像高度,B个主成分数目。
为了利用图像进行分类,将高光谱数据分成互相重叠的3D块,中心像素的标签作为其的真值。我们制作X内所有像元的3D块,大小为window SizeS*S,B的厚度。共可获得数据块的数量为(M-S+1)*(M-S+1)。这样,在以坐标(α,β)为中心位置的3D块上,表示为Pα,β,宽度从α − (S − 1)/2到 α + (S − 1)/2,高度从β − (S − 1)/2到 β + (S − 1)/2,B是经过PCA后的主成分。
在2D-CNN中,输入数据被2D卷积核处理。通过点乘求和完成卷积过程。卷积核扫过全幅数据,再通过非线性激活函数获得特征图。在2D-CNN中,在第i层的第j个特征图,空间位置(x,y)的激活值表示可以由公式获得(公式略)。
在3D-CNN中,卷积是在3D数据上进行3D卷积核的处理。对于高光谱数据,输入层是连续的多波段,通过3D卷积核操作生成特征图来捕获光谱信息。在3D-CNN中,第i层的第j个特征图,空间位置(x,y,z)的激活值表示可以由公式获得(公式略)。
CNN的参数,如偏置b和权重w,通常由梯度下降优化算法通过监督训练得出。传统的2D-CNN,卷积仅应用到了空间维度,覆盖所有特征图。2D-CNN对光谱信息不进行处理。3D-CNN同时对光谱和空间信息进行处理,但增加了计算复杂度。为了获得2D-CNN和3D-CNN的自动学习能力,我们提出混合CNN。流程图如图1所示,包含了3D卷积层、2D卷积层和全连接层。
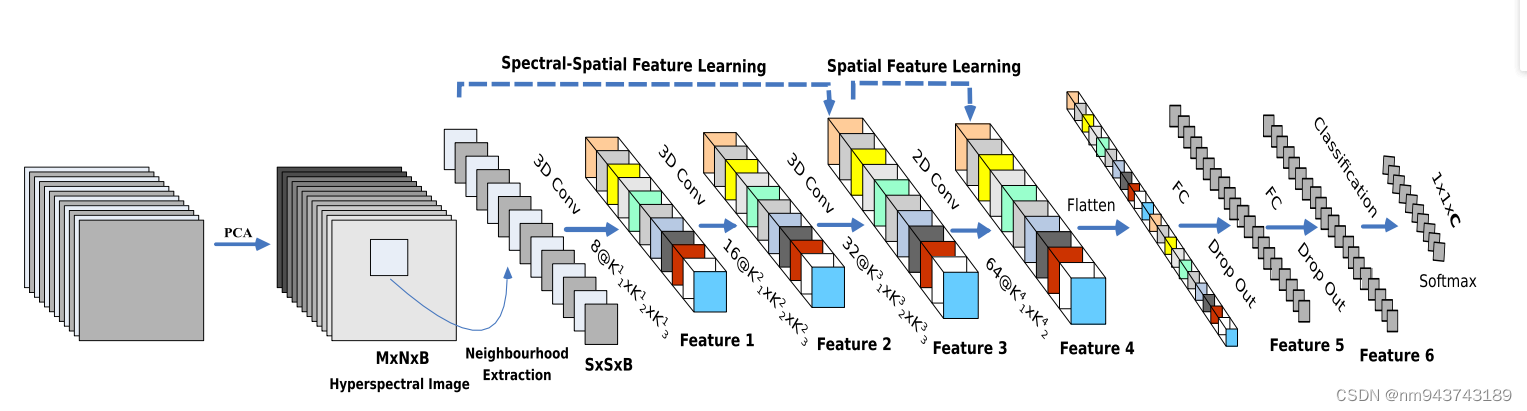
图1
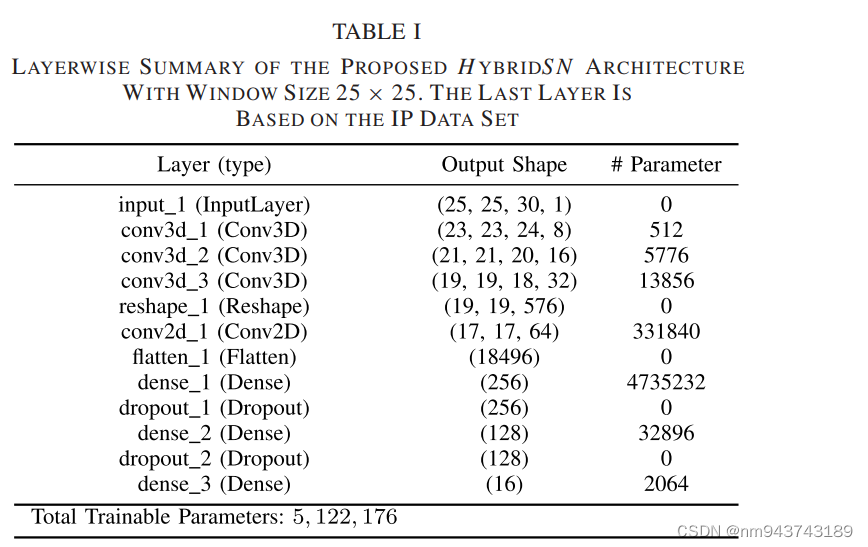
在混合CNN中,3D卷积核的维度为 8 × 3 × 3 × 7 × 1(即:8个3*3*7)、16 × 3 × 3 × 5 × 8(即16个3 × 3 × 5 )、32 × 3 × 3 × 3 × 16(即32个3*3*3)在随后的第一、第二、第三卷积层,16×3×3×5×8表示16个3D卷积核,维度为3*3*5(即两个空间维度和一个光谱维度)对于所有的8个3D输入特征图。另一方面,2D卷积核64 × 3 × 3 × 576(即3*3的空间维度),64代表2D卷积核的数量,576代表2D输入特征图的数量。为了同时增加空谱特征图的数量,3D卷积被应用了3次将光谱信息保留到输出。2D卷积被应用了一次,在flatten层前,用于区分空间信息中不同光谱波段中不含实质性光谱信息损失???。表I是混合CNN的分层结构,window Size=25*25。可以看出在第一个dense层具有大量的参数,最后一个dense层节点数目为16,是由于Indian Pines分类数目决定的。这个数据集的训练权重总数为5122176个。所有的权重均为随机初始化并由BP反向传播算法训练,Adam优化器和softmax计算loss。我们使用minibatch=256,epochs=100进行网络训练,不含BN层和数据增强处理。
III. EXPERIMENTS AND DISCUSSION
A数据集情况和训练过程
我们使用三个公开数据集,Indian Pines(IP),University of Pavia(UP)和Salinas Scene(SA).IP数据集空间维145*145具有224个波段,光谱范围400-2500nm,有24个水份吸收带被舍弃。地面真值包括16种植被。UP数据集空间维度610*340,在430-860nm光谱范围内有103个波段。地面真值包括9个土地覆盖类型。SA数据集空间维度512*217,在360-2500nm具有224个光谱波段。20个水份吸收波段被舍弃。共有16个地物类别。
所有实验都是在GTX1060GPU的Acer Predator-Helios笔记本上跑出,具有16G的RAM。我们选择最佳学习率为0.001。为了进行比较,我们对IP进行了25*25*30和UP及SA25*25*15的3Dpatches操作,完成同样空间维度的提取。
B分类结果
本文使用OA、AA、卡帕系数作为评价指标。这里,OA表示总体测试样本中被正确分类的数目;AA表示平均分类精度;卡帕系数是个统计的矩阵可提供真值和分类结果的信息。混合CNN与SVM、2D-CNN、3D-CNN、多尺度3D-CNN神经网络、SSRN进行对比。训练数据和测试数据按照30%和70%进行随机划分。
表II展示了各种方法得到的OA、AA、卡帕系数。可以从表II看出混合CNN优于其他方法。具有最小标准差。本文提出的3D-CNN连接2D-CNN性能上互补。还可看出在SA数据集上,3D-CNN表现不如2D-CNN。可能是由于SA数据集中两类地物在大多数光谱波段上具有相似的纹理造成的。因此,光谱波段导致的冗余使得2D-CNN优于3D-CNN。此外,SSRN和混合CNN性能均优于M3D-CNN。这表明单独的3D-CNN或2D-CNN与混合CNN比较,不能提取出更高的区分特征。

图2展示出这几种方法的分类图。SSRN和混合CNN效果优于其余方法。在二者间,混合CNN对于细小地物分类优于SSRN。
 图3展示了混合CNN对于以上三种数据集的混淆矩阵。
图3展示了混合CNN对于以上三种数据集的混淆矩阵。
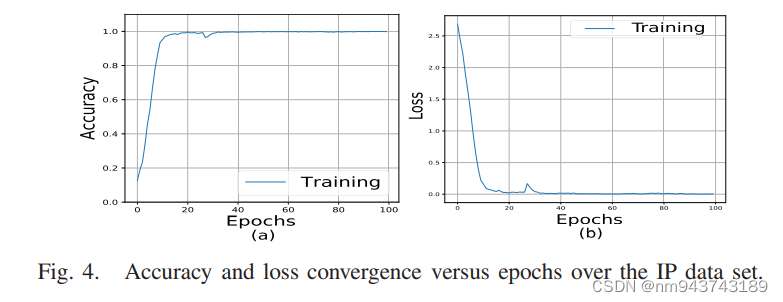
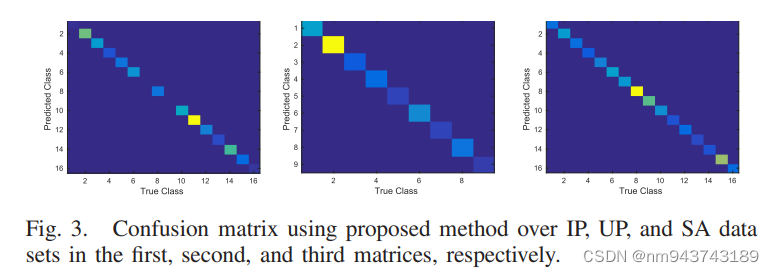 图4展示了混合CNN的epoch=100的训练集和验证集上的准确率及损失值。可以看出在epochs=50时收敛。
图4展示了混合CNN的epoch=100的训练集和验证集上的准确率及损失值。可以看出在epochs=50时收敛。
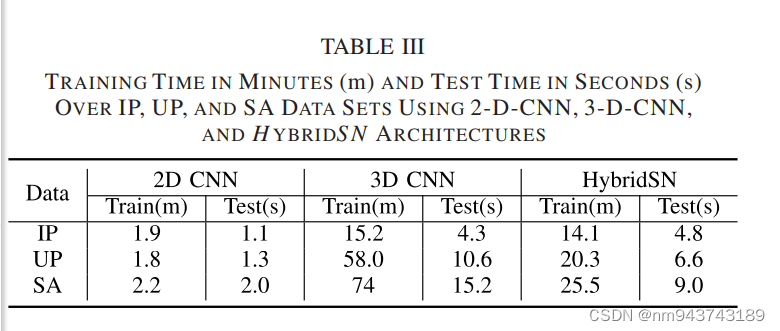
 表III显示了混合模型在训练和预测的时间。其比3D-CNN更高效。
表III显示了混合模型在训练和预测的时间。其比3D-CNN更高效。
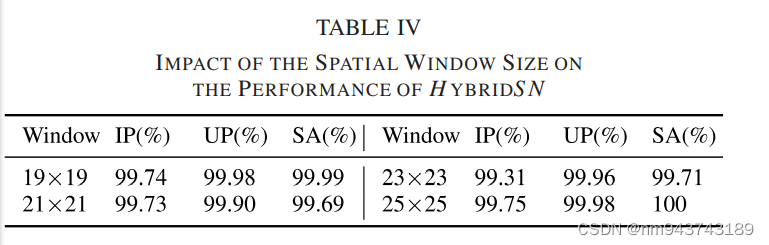
表IV展示了25*25窗口尺寸影响的结果。可以看出25*25的尺度是最合适本方法的。
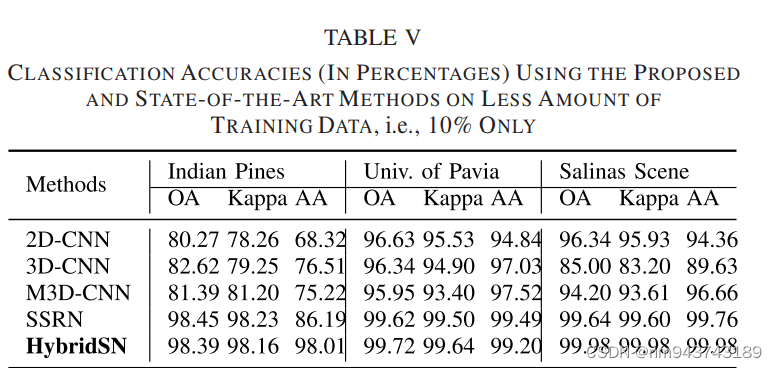
表V展示了使用10%的样本和结果。可以看出,各个模型的性能均轻微下降,而本文提出的方法仍优于其他方法。
IV结论
本文介绍了一种混合3D卷积和2D卷积的方法 。可将3D卷积和2D卷积的优势进行互补。通过三个数据集与当前方法进行对比,证实了本文方法具有优越性。该模型的计算效率优于3D-CNN。也适用于小数量训练数据。










 京公网安备 11010802041100号
京公网安备 11010802041100号